ShuffleNetV1pytorch代码实战
本文概述
- 使用pytorch在MNIST数据集上,实战ShuffleNetV1
- 本文参考同济子豪兄b站视频; ShuffleNet-Series
核心算法
group pointwise convolution:分组1*1卷积
常规卷积操作
- 对于一张
5*5*3的输入 - 经过
3×3卷积核的卷积层(假设输出channel=4,则卷积核shape=3*3*3*4), 最终输出4个Feature Map - 如果有
same padding则尺寸与输入层相同(5*5),如果没有则尺寸变为3*3 - 如果有
stride和padding,输出尺寸计算公式如下
depthwise convolution
- 一个卷积核负责一个通道,一个通道只被一个卷积核卷积
- 卷积核的数量与上一层的通道数相同
- 相比常规卷积的好处在于参数量少,模型可以做得更深
pointwise convolution
1*1卷积核
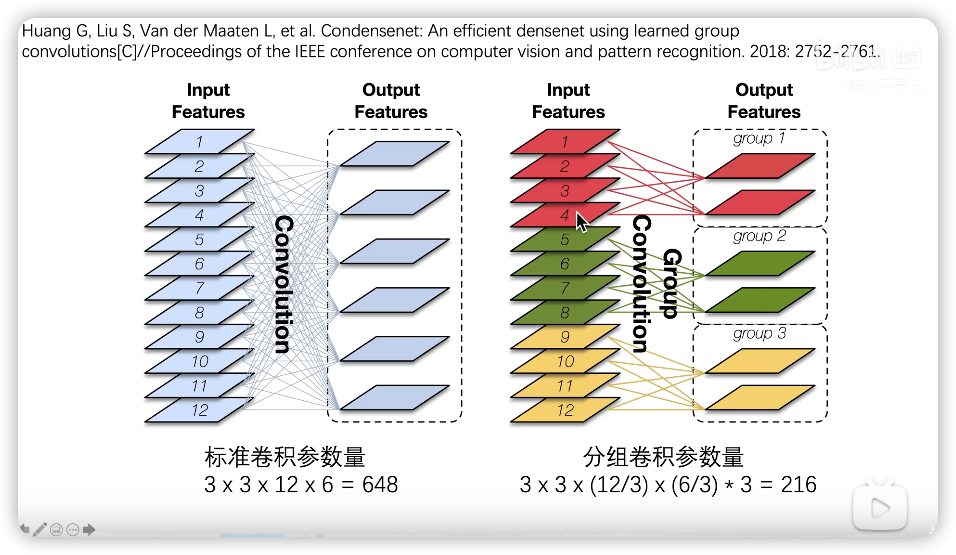
group convolution
- 将通道数一分为
n组, 每组单独使用卷积核进行卷积,互不干扰 - 如图

- 卷积核的尺寸为
1×1×m,m为上一层的通道数 - 相比常规卷积的好处在于参数量少,模型可以做得更深
channel shuffle: 通道重排
- 为了防止近亲繁殖:也就是组与组之间老死不相往来而设定,如下图


网络结构
- 如下图


导入module
import torch
import torchvision
from torchvision import transforms
from torchinfo import summary
from torch.utils.data import DataLoader
参数设置
# 设置随机数,便于复现
my_seed = 2030
torch.manual_seed(my_seed)
# gpu or cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 是否加速卷积运算
torch.backends.cudnn.benchmark = False
batch_size = 32
models_dir_path = './models/ShuffleNetV1'
logs_dir_path = './logs/ShuffleNetV1'
device
device(type='cpu')
加载数据集
train_dataset = torchvision.datasets.MNIST(root='./datasets/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./datasets/',
train=False,
transform=transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
for x, y in train_loader:
print(x.shape, y.shape)
print(x.size(), y.size())
break
torch.Size([32, 1, 28, 28]) torch.Size([32])
torch.Size([32, 1, 28, 28]) torch.Size([32])
utils.py
- LogSoftmax公式
import os
import re
import torch
import torch.nn as nn
class CrossEntropyLabelSmooth(nn.Module):
"""
标签平滑(Label Smoothing)是一个有效的正则化方法,可以在分类任务中提高模型的泛化能力。
其思想相当简单,即在通常的Softmax-CrossEntropy中的OneHot编码上稍作修改,将非目标类概率值设置为一个小量,相应地在目标类上减去一个值,从而使得标签更加平滑
"""
def __init__(self, num_classes, epsilon):
super(CrossEntropyLabelSmooth, self).__init__()
self.num_classes = num_classes # 分类数量
self.epsilon = epsilon # 小量
self.logsoftmax = nn.LogSoftmax(dim=1) # log soft Max函数,按行soft Max,即每行元素soft Max总和为1
def forward(self, inputs, targets):
# inputs是yi^hat,即预测值,targets是真实值
log_probs = self.logsoftmax(inputs)
# 和log_probs一样的size,以targets填充
# PyTorch 中,一般函数加下划线代表直接在原来的 Tensor 上修改
targets = torch.zeros_like(log_probs).scatter_(dim=1, index=targets.unsqueeze(1), value=1) # 用value替换dim=1方向对应index位置的数
targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes # 标签平滑
loss = (-targets * log_probs).mean(0).sum() # 按列求均值,再求和
return loss
# 测试
num_classes = 8
batch_size = 32
test_inputs = torch.randn(batch_size, num_classes)
test_targets = torch.randint(low=0, high=num_classes-1, size=[batch_size])
print(test_inputs.size(), test_targets.size())
label_smoth_class = CrossEntropyLabelSmooth(num_classes=num_classes, epsilon=0.1)
label_smoth_loss = label_smoth_class(test_inputs, test_targets)
label_smoth_loss
torch.Size([32, 8]) torch.Size([32])
tensor(2.5863)
class AvgrageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.avg = 0
self.sum = 0
self.cnt = 0
self.val = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
def accuracy(output, target, topk=(1,)):
"""
计算topk正确率
"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(k=maxk, dim=1, largest=True, sorted=True) # 每行取出topk的类别
pred = pred.t() # pred转至
correct = pred.eq(target.view(1, -1).expand_as(pred)) # view相当于reshape, expand_as
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0/batch_size))
return res
# 测试
num_classes = 8
batch_size = 32
test_inputs = torch.randn(batch_size, num_classes)
test_targets = torch.randint(low=0, high=num_classes-1, size=[batch_size])
print(test_inputs.size(), test_targets.size())
print(accuracy(test_inputs, test_targets))
torch.Size([32, 8]) torch.Size([32])
[tensor(6.2500)]
def save_checkpoint(models_dir_path, state, iters, tag=''):
"""
保存checkpoint
:param models_dir_path: 模型保存路径
:param state: 模型
:param iters: 第几步
:param tag: 标签名
"""
if not os.path.exists(models_dir_path):
os.makedirs(models_dir_path)
filename = os.path.join('{}/{}checkpoints-{:06}.pth.tar'.format(models_dir_path, tag, iters))
torch.save(state, filename)
def get_lastest_model(models_dir_path):
"""
获取最新模型的路径+文件名
:param models_dir_path: 模型保存路径
"""
if not os.path.exists(models_dir_path):
os.makedirs(models_dir_path)
models_list = os.listdir(models_dir_path)
if models_list == []:
return None, 0
models_list.sort()
lastest_model = models_list[-1]
iters = re.findall(r'\d+', lastest_model)
return os.path.join(models_dir_path, lastest_model), int(iters[0])
def get_parameters(model):
"""
获取模型参数值
:param model: 模型实例
"""
group_no_weight_decay = []
group_weight_decay = []
for pname, p in model.named_parameters():
if pname.find('weight') >= 0 and len(p.size()) > 1:
group_weight_decay.append(p)
else:
group_no_weight_decay.append(p)
assert len(list(model.parameters())) == len(group_no_weight_decay) + len(group_weight_decay)
groups = [dict(params=group_weight_decay), dict(params=group_no_weight_decay, weight_decay=0.)]
return groups
blocks.py
- Conv2d
In the simplest case, the output value of the layer with input size
$(N, C_{\text{in}}, H, W)$ and output $(N, C_{\text{out}}, H_{\text{out}}, W_{\text{out}})$
can be precisely described as:
where $\star$ is the valid 2D cross-correlation_ operator,
$N$ is a batch size, $C$ denotes a number of channels,
$H$ is a height of input planes in pixels, and $W$ is
width in pixels.
- BatchNorm2d
The mean and standard-deviation are calculated per-dimension over
the mini-batches and $\gamma$ and $\beta$ are learnable parameter vectors
of size $C$ (where $C$ is the input size). By default, the elements of $\gamma$ are set
to 1 and the elements of $\beta$ are set to 0. The standard-deviation is calculated
via the biased estimator, equivalent to torch.var(input, unbiased=False).
- AvgPool2d
In the simplest case, the output value of the layer with input size $(N, C, H, W)$,
output $N, C, H_{out}, W_{out})$ and kernel_size $(kH, kW)$
can be precisely described as:
If :attr:padding is non-zero, then the input is implicitly zero-padded on both sides
for :attr:padding number of points.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleV1Block(nn.Module):
# * 后面是限制命名关键字参数,**kw是命名关键字参数,可以传任意多参数
def __init__(self, inp, oup, *, group, first_group, mid_channels, ksize, stride):
super(ShuffleV1Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize # kernel size
pad = ksize // 2 # padding
self.pad = pad
self.inp = inp
self.group = group # 分组数
if stride == 2:
# 方便下采样concat拼接
outputs = oup - inp
else:
outputs = oup
branch_main_1 = [
# ponitwise 1*1分组卷积降维
nn.Conv2d(in_channels=inp,
out_channels=mid_channels,
kernel_size=1,
stride=1,
padding=0,
groups=1 if first_group else group,
bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# depthwise 3*3 depth卷积
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
]
branch_main_2 = [
# pointwise-linear 1*1分组卷积升维
nn.Conv2d(mid_channels, outputs, 1, 1, 0, groups=group, bias=False),
nn.BatchNorm2d(outputs),
]
self.branch_main_1 = nn.Sequential(*branch_main_1)
self.branch_main_2 = nn.Sequential(*branch_main_2)
if stride == 2:
# 下采样concat拼接
self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
def channel_shuffle(self, x):
batch_size, num_channels, height, width = x.data.size()
assert num_channels % self.group == 0
group_channels = num_channels // self.group # 计算每个组多少channel数
x = x.reshape(batch_size, group_channels, self.group, height, width)
x = x.permute(0, 2, 1, 3, 4) # 转置
x = x.reshape(batch_size, num_channels, height, width)
return x
def forward(self, old_x):
x = old_x
x_proj = old_x
x = self.branch_main_1(x)
if self.group > 1:
x = self.channel_shuffle(x)
x = self.branch_main_2(x)
if self.stride == 1:
# 是我们设计出的strid=1的ShuffleNet单元,
# 首先进行了1*1的Gconv(分组卷积),
# 然后接了通道重排(channel shuffle),
# 然后是3*3dw卷积(深度可分离卷积,即各通道做各自的),但是后边我们并没有接relu,
# 最后再add操作
return F.relu(x + x_proj)
elif self.stride == 2:
# 我们设计出了strid=2的ShuffleNet单元,其在残差边上使用了3*3的平均池化,
# 注意最后是concat操作,而不是add操作,这样可以不增加计算量的前提下扩大特征维度,(add是通道数值相加,concat是通道堆叠)
# 举个例子,所以这里是432+48=480 channels
return torch.cat((self.branch_proj(x_proj), F.relu(x)), 1)
network.py
import torch
import torch.nn as nn
# from blocks import ShuffleV1Block
class ShuffleNetV1(nn.Module):
def __init__(self, input_size=224, n_class=1000, model_size='2.0x', group=None):
super(ShuffleNetV1, self).__init__()
print('model size is ', model_size)
assert group is not None
self.stage_repeats = [4, 8, 4]
self.model_size = model_size
if group == 3:
if model_size == '0.5x':
self.stage_out_channels = [-1, 12, 120, 240, 480]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 240, 480, 960]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 360, 720, 1440]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 480, 960, 1920]
else:
raise NotImplementedError
elif group == 8:
if model_size == '0.5x':
self.stage_out_channels = [-1, 16, 192, 384, 768]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 384, 768, 1536]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 576, 1152, 2304]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 768, 1536, 3072]
else:
raise NotImplementedError
# building first layer
input_channel = self.stage_out_channels[1] # 第一层输出channel
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=input_channel,
kernel_size=3,
stride=2,
padding=1,
bias=False),
nn.BatchNorm2d(input_channel),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# stage阶段
self.features = []
for idx_stage in range(len(self.stage_repeats)):
num_repeat = self.stage_repeats[idx_stage]
output_channel = self.stage_out_channels[idx_stage+2]
for i in range(num_repeat):
stride = 2 if i == 0 else 1
first_group = idx_stage == 0 and i == 0
self.features.append(ShuffleV1Block(input_channel, output_channel,
group=group, first_group=first_group,
mid_channels=output_channel // 4,
ksize=3, stride=stride))
input_channel = output_channel
self.features = nn.Sequential(*self.features)
self.globalpool = nn.AvgPool2d(7)
self.classifier = nn.Sequential(
nn.Linear(self.stage_out_channels[-1], n_class, bias=False)
)
self._initialize_weights()
def forward(self, x):
x = self.first_conv(x)
x = self.maxpool(x)
x = self.features(x)
x = self.globalpool(x)
x = x.contiguous().view(-1, self.stage_out_channels[-1])
x = self.classifier(x)
return x
def _initialize_weights(self):
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
if 'first' in name:
nn.init.normal_(m.weight, 0, 0.01)
else:
nn.init.normal_(m.weight, 0, 1.0/m.weight.shape[1])
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0.0001)
nn.init.constant_(m.running_mean, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
model = ShuffleNetV1(group=3)
summary(model)
model size is 2.0x
=================================================================
Layer (type:depth-idx) Param #
=================================================================
ShuffleNetV1 --
├─Sequential: 1-1 --
│ └─Conv2d: 2-1 1,296
│ └─BatchNorm2d: 2-2 96
│ └─ReLU: 2-3 --
├─MaxPool2d: 1-2 --
├─Sequential: 1-3 --
│ └─ShuffleV1Block: 2-4 --
│ │ └─Sequential: 3-1 7,320
│ │ └─Sequential: 3-2 18,144
│ │ └─AvgPool2d: 3-3 --
│ └─ShuffleV1Block: 2-5 --
│ │ └─Sequential: 3-4 20,760
│ │ └─Sequential: 3-5 20,160
│ └─ShuffleV1Block: 2-6 --
│ │ └─Sequential: 3-6 20,760
│ │ └─Sequential: 3-7 20,160
│ └─ShuffleV1Block: 2-7 --
│ │ └─Sequential: 3-8 20,760
│ │ └─Sequential: 3-9 20,160
│ └─ShuffleV1Block: 2-8 --
│ │ └─Sequential: 3-10 41,520
│ │ └─Sequential: 3-11 39,360
│ │ └─AvgPool2d: 3-12 --
│ └─ShuffleV1Block: 2-9 --
│ │ └─Sequential: 3-13 79,920
│ │ └─Sequential: 3-14 78,720
│ └─ShuffleV1Block: 2-10 --
│ │ └─Sequential: 3-15 79,920
│ │ └─Sequential: 3-16 78,720
│ └─ShuffleV1Block: 2-11 --
│ │ └─Sequential: 3-17 79,920
│ │ └─Sequential: 3-18 78,720
│ └─ShuffleV1Block: 2-12 --
│ │ └─Sequential: 3-19 79,920
│ │ └─Sequential: 3-20 78,720
│ └─ShuffleV1Block: 2-13 --
│ │ └─Sequential: 3-21 79,920
│ │ └─Sequential: 3-22 78,720
│ └─ShuffleV1Block: 2-14 --
│ │ └─Sequential: 3-23 79,920
│ │ └─Sequential: 3-24 78,720
│ └─ShuffleV1Block: 2-15 --
│ │ └─Sequential: 3-25 79,920
│ │ └─Sequential: 3-26 78,720
│ └─ShuffleV1Block: 2-16 --
│ │ └─Sequential: 3-27 159,840
│ │ └─Sequential: 3-28 155,520
│ │ └─AvgPool2d: 3-29 --
│ └─ShuffleV1Block: 2-17 --
│ │ └─Sequential: 3-30 313,440
│ │ └─Sequential: 3-31 311,040
│ └─ShuffleV1Block: 2-18 --
│ │ └─Sequential: 3-32 313,440
│ │ └─Sequential: 3-33 311,040
│ └─ShuffleV1Block: 2-19 --
│ │ └─Sequential: 3-34 313,440
│ │ └─Sequential: 3-35 311,040
├─AvgPool2d: 1-4 --
├─Sequential: 1-5 --
│ └─Linear: 2-20 1,920,000
=================================================================
Total params: 5,449,776
Trainable params: 5,449,776
Non-trainable params: 0
=================================================================
test_data = torch.rand(5, 3, 224, 224)
test_data.size()
torch.Size([5, 3, 224, 224])
test_outputs = model(test_data)
print(test_outputs.size())
torch.Size([5, 1000])
test_outputs
tensor([[ 0.3845, -0.2636, -0.4430, ..., -0.6833, -0.5021, 0.2242],
[ 0.3387, -0.2145, -0.3742, ..., -0.6619, -0.5104, 0.1868],
[ 0.4063, -0.4180, -0.2883, ..., -0.5225, -0.6099, 0.0852],
[ 0.2605, -0.1629, -0.4033, ..., -0.6487, -0.4731, 0.1499],
[ 0.2464, -0.3109, -0.5411, ..., -0.6478, -0.5235, 0.0668]],
grad_fn=<MmBackward0>)
train.py
import os
import sys
import torch
import argparse
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import cv2
# pip install opencv-python
import numpy as np
import PIL
from PIL import Image
import time
import logging
class OpencvResize(object):
"""
利用opencv进行图片resize
"""
def __init__(self, size=256):
self.size = size
def __call__(self, img):
assert isinstance(img, PIL.Image.Image)
img = np.asarray(img) # (H, W, 3) RGB
img = img[:, :, ::-1] # BGR
img = np.ascontiguousarray(img) # Return a contiguous array (ndim >= 1) in memory (C order).
H, W, _ = img.shape
# 按长宽比进行缩放
target_size = (int(self.size / H * W + 0.5), self.size) if H < W else (self.size, int(self.size / W * H + 0.5))
img = cv2.resize(img, target_size, interpolation=cv2.INTER_LINEAR) # 插值
img = img[:, :, ::-1] # RGB
img = np.ascontiguousarray(img)
img = Image.fromarray(img)
return img
img_path = '../images/group_convolution.png'
img = Image.open(img_path)
print(img.size)
img
(956, 555)
img_resize = OpencvResize(256)(img)
print(img_resize.size)
img_resize
(441, 256)
class ToBGRTensor(object):
"""
转为BGRTensor
"""
def __call__(self, img):
assert isinstance(img, (np.ndarray, PIL.Image.Image))
if isinstance(img, PIL.Image.Image):
img = np.asarray(img)
img = img[:, :, ::-1] # 2 BGR
img = np.transpose(img, [2, 0, 1]) # 2 [3, H, W]
img = np.ascontiguousarray(img) # 将一个内存不连续存储的数组转换为内存连续存储的数组,使得运行速度更快
img = torch.from_numpy(img).float()
return img
img_tensor = ToBGRTensor()(img_resize)
img_tensor.shape
torch.Size([4, 256, 441])
class DataIterator(object):
"""
数据导入类
"""
def __init__(self, dataloader):
self.dataloader = dataloader
self.iterator = enumerate(self.dataloader)
def next(self):
try:
_, data = next(self.iterator)
except Exception:
self.iterator = enumerate(self.dataloader)
_, data = next(self.iterator)
return data[0], data[1]
def get_args():
"""
获取运行参数
"""
parser = argparse.ArgumentParser('ShuffleNetV1')
parser.add_argument('--eval', default=False, action='store_true')
parser.add_argument('--eval-resume', type=str, default='./models/snet_detnas.pkl', help='path for eval model')
parser.add_argument('--batch-size', type=int, default=1024, help='batch size')
parser.add_argument('--total-iters', type=int, default=300000, help='total iters')
parser.add_argument('--learning-rate', type=float, default=0.5, help='init learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
parser.add_argument('--weight-decay', type=float, default=4e-5, help='weight decay')
parser.add_argument('--save', type=str, default='./models', help='path for saving trained models')
parser.add_argument('--label-smooth', type=float, default=0.1, help='label smoothing')
parser.add_argument('--auto-continue', type=bool, default=True, help='auto continue')
parser.add_argument('--display-interval', type=int, default=20, help='display interval')
parser.add_argument('--val-interval', type=int, default=10000, help='val interval')
parser.add_argument('--save-interval', type=int, default=10000, help='save interval')
parser.add_argument('--group', type=int, default=3, help='group number')
parser.add_argument('--model-size', type=str, default='2.0x', choices=['0.5x', '1.0x', '1.5x', '2.0x'], help='size of the model')
parser.add_argument('--train-dir', type=str, default='./datasets/train', help='path to training dataset')
parser.add_argument('--val-dir', type=int, default=20, help='path to validation dataset')
args = parser.parse_args()
return args
# args = get_args()
# args
def load_checkpoint(net, checkpoint):
"""
导入模型
"""
from collections import OrderedDict
temp = OrderedDict()
if 'state_dict' in checkpoint:
checkpoint = dict(checkpoint['state_dict'])
for k in checkpoint:
k2 = 'module.' + k if not k.startswith('module.') else k
temp[k2] = checkpoint[k]
net.load_state_dict(temp, strict=True)
def validate(model, device, args, *, all_iters=None):
"""
利用现有模型对验证集数据进行推断评估
"""
objs = AvgrageMeter()
top1 = AvgrageMeter()
top5 = AvgrageMeter()
loss_function = args.loss_function
val_dataprovider = args.val_dataprovider
model.eval()
max_val_iters = 250
t1 = time.time()
with torch.no_grad():
for _ in range(1, max_val_iters+1):
data, target = val_dataprovider.next()
target = target.type(torch.LongTensor)
data, target = data.to(device), target.to(device)
output = model(data)
loss = loss_function(output, target)
prec1, prec5 = accuracy(output, target, topk=(1, 5))
n = data.size(0)
objs.update(loss.item(), n)
top1.update(prec1.item(), n)
top5.update(prec5.item(), n)
logInfo = 'TEST Iter {}: loss = {:.6f},\t'.format(all_iters, objs.avg) + \
'Top-1 err = {:.6f},\t'.format(1 - top1.avg / 100) + \
'Top-5 err = {:.6f},\t'.format(1 - top5.avg / 100) + \
'val_time = {:.6f}'.format(time.time() - t1)
logging.info(logInfo)
def adjust_bn_momentum(model, iters):
"""
调整batch normalization的momentum
"""
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.momentum = 1 / iters
def train(model, device, args, *, val_interval, bn_process=False, all_iters=None):
"""
训练过程
"""
optimizer = args.optimizer
loss_function = args.loss_function
scheduler = args.scheduler
train_dataprovider = args.train_dataprovider
t1 = time.time()
Top1_err, Top5_err = 0.0, 0.0
model.train()
for iters in range(1, val_interval + 1):
scheduler.step()
if bn_process:
adjust_bn_momentum(model, iters)
all_iters += 1
d_st = time.time()
data, target = train_dataprovider.next()
target = target.type(torch.LongTensor)
data, target = data.to(device), target.to(device)
data_time = time.time() - d_st
output = model(data)
loss = loss_function(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
prec1, prec5 = accuracy(output, target, topk=(1, 5))
Top1_err += 1 - prec1.item() / 100
Top5_err += 1 - prec5.item() / 100
if all_iters % args.display_interval == 0:
printInfo = 'TRAIN Iter {}: lr = {:.6f},\tloss = {:.6f},\t'.format(all_iters, scheduler.get_lr()[0], loss.item()) + \
'Top-1 err = {:.6f},\t'.format(Top1_err / args.display_interval) + \
'Top-5 err = {:.6f},\t'.format(Top5_err / args.display_interval) + \
'data_time = {:.6f},\ttrain_time = {:.6f}'.format(data_time, (time.time() - t1) / args.display_interval)
logging.info(printInfo)
t1 = time.time()
Top1_err, Top5_err = 0.0, 0.0
if all_iters % args.save_interval == 0:
save_checkpoint({
'state_dict': model.state_dict(),
}, all_iters)
return all_iters
def main():
args = get_args()
# Log
log_format = '[%(asctime)s] %(message)s'
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format=log_format, datefmt='%d %I:%M:%S')
t = time.time()
local_time = time.localtime(t)
if not os.path.exists(logs_dir_path):
os.makedirs(logs_dir_path)
fh = logging.FileHandler(os.path.join('{}/train-{}{:02}{}'.format(logs_dir_path, local_time.tm_year % 2000, local_time.tm_mon, t)))
fh.setFormatter(logging.Formatter(log_format))
logging.getLogger().addHandler(fh)
use_gpu = False
if torch.cuda.is_available():
use_gpu = True
# 导入数据
assert os.path.exists(args.train_dir)
train_dataset = datasets.ImageFolder(
args.train_dir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
transforms.RandomHorizontalFlip(0.5),
ToBGRTensor(),
])
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=1, pin_memory=use_gpu
)
train_dataprovider = DataIterator(train_loader)
assert os.path.exists(args.val_dir)
val_dataset = datasets.ImageFolder(
args.val_dir,
transforms.Compose([
OpencvResize(256),
transforms.CenterCrop(224),
ToBGRTensor(),
])
)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=200, shuffle=False,
num_workers=1, pin_memory=use_gpu
)
val_dataprovider = DataIterator(val_loader)
print('load data successfully')
# 构建模型
model = ShuffleNetV1(group=args.group, model_size=args.model_size)
# 构建优化器
optimizer = torch.optim.SGD(get_parameters(model),
lr=args.learning_rate,
momentum=args.momentum,
weight_decay=args.weight_decay)
# 构建损失函数
criterion_smooth = CrossEntropyLabelSmooth(1000, 0.1)
if use_gpu:
model = nn.DataParallel(model)
loss_function = criterion_smooth.cuda()
device = torch.device('cuda')
else:
loss_function = criterion_smooth
device = torch.device('cpu')
# learning_rate随着训练步数调整
scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer,
lambda step: (1.0-step/args.total_iters) if step <= args.total_iters else 0,
last_epoch=-1
)
model = model.to(device)
# 是否往上次训练的地方开始继续训练
all_iters = 0
if args.auto_continue:
lastest_model, iters = get_lastest_model()
if lastest_model is not None:
all_iters = iters
checkpoint = torch.load(lastest_model, map_location=None if use_gpu else 'cpu')
model.load_state_dict(checkpoint['state_dict'], strict=True)
print('load from checkpoint')
for i in range(iters):
scheduler.step()
args.optimizer = optimizer
args.loss_function = loss_function
args.scheduler = scheduler
args.train_dataprovider = train_dataprovider
args.val_dataprovider = val_dataprovider
# 如果是线上推断
if args.eval:
if args.eval_resume is not None:
checkpoint = torch.load(args.eval_resume, map_location=None if use_gpu else 'cpu')
load_checkpoint(model, checkpoint)
validate(model, device, args, all_iters=all_iters)
exit(0)
# 如果没达到设定的训练步数,则需要继续训练
while all_iters < args.total_iters:
all_iters = train(model, device, args, val_interval=args.val_interval, bn_process=False, all_iters=all_iters)
validate(model, device, args, all_iters=all_iters)
all_iters = train(model, device, args, val_interval=int(1280000/args.batch_size), bn_process=True, all_iters=all_iters)
validate(model, device, args, all_iters=all_iters)
# 保存模型
save_checkpoint({'state_dict': model.state_dict(), }, args.total_iters, tag='bnps-')
torch.save(model.state_dict(), models_dir_path+'/model.mdl')


