
基础
- 决策树既可以分类、也可以回归
- 又适合集成学习如随机森林、GBDT
算法
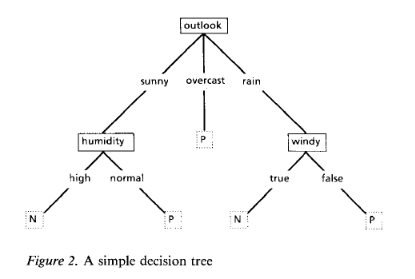
输入训练集$T = \lbrace (x_1,y_1),(x_2,y_2), \cdots ,(x_n,y_n) \rbrace$,构建如下图的一棵树
面临的2个问题
如何选择特征进行分裂
- 显而易见,划分后每个节点内的样本类别混乱程度越低(纯度越高),则应该优先划分这个特征
啥时候停止分裂
- 有两种自然情况应该停止分裂
- 一是该节点对应的所有样本记录均属于同一类别,
- 二是该节点对应的所有样本的特征属性值均相等。
- 但除此之外,是不是还应该其他情况停止分裂呢?
- 使用剪枝方法提高模型的泛化能力
- 预剪枝
- 后剪枝
混乱程度的度量
熵:越混乱越大
- $t$:某个特征节点
- $c_k$:样本所属类别
- $p(c_k|t)$:$t$节点的$c_k$类别对应样本比例,
- 例如D节点有15个样本,输出为0或者1。其中有9个输出为1, 6个输出为0,则类别1的样本比例为:$9/15$
GINI系数:越混乱越大
总结
| 算法 | 模型 | 树结构 | 特征选择 | 连续值 | 缺失值 | 剪枝 |
|---|---|---|---|---|---|---|
ID3 |
分类 | 多叉 | 信息增益 | no | no | no |
C4.5 |
分类 | 多叉 | 信息增益率 | yes | yes | yes |
CART |
分裂、回归 | 二叉 | gini、均方差 |
yes | yes | yes |
进阶
ID3:至少二叉
分裂目标函数:信息增益,越大,越适合
- $a_i$:$parent$节点根据特征$X$分裂成的子节点
- $N$:$parent$节点对应的样本量
- $N(a_i)$:$a_i$节点对应的样本量
算法步骤
- 输入:
- $m$个样本,样本类别集合$D$,
- 每个样本有$n$个
离散特征,特征集合$A$
- 输出:
- 决策树$T$
- 过程
- 初始化信息增益的阈值$\epsilon$
- 判断是否满足自然分裂条件:
- 判断样本是否为同一类别输出$L_i$,如果是则返回单节点树$T$。标记类别为$L_i$
- 判断特征是否为空,如果是则返回单节点树$T$。标记类别为样本类别集合$D$中实例数最多的类别
- 计算特征集合$A$中的各个特征对$D$的
信息增益,选择信息增益最大的特征$A_g$进行分裂 - 如果$A_g$的信息增益小于$\epsilon$,则返回单节点数$T$,标记类别为样本类别集合$D$中实例数最多的类别
- 否则,按特征$A_g$的不同取值将对应样本类别$D$分成不同的类别集合$D_i$。每个类别产生一个子节点,对应特征值为$A_{gi}$。返回增加了节点的树$T$
- 对于所有的子节点,令$D=D_i,A=A-\{A_g\}$,重复2-6步
- 得到树$T$
优缺点
- 缺点:
- 没有考虑
连续特征 - 没有考虑
缺失值 - 分裂目标函数使用信息增益的方式,在相同条件下,取值比较多的特征比取值少的特征信息增益大,这样会有失偏颇
- 没有考虑过拟合问题
- 没有考虑
C4.5:至少二叉,对ID3的改进版
改进的地方
- 对连续特征离散化,要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程
- 针对缺失值处理,主要需要解决的是以下两个问题
- 一是在某个特征有缺失值时,怎么分裂这个特征
- 将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据
D1,另一部分是没有特征A的数据D2 - 然后对于没有缺失特征A的数据集
D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比, - 最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例
- 将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据
- 二是选定了划分属性,对于在该属性上缺失样本应该如何处理
- 可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。
- 比如缺失特征A的样本a之前权重为1,特征A有3个特征值
A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
- 一是在某个特征有缺失值时,怎么分裂这个特征
- 信息增益作为标准容易偏向于取值较多的特征的问题。
C4.5引入一个信息增益比的变量 C4.5引入了正则化系数进行初步的剪枝,处理过拟合问题
分裂目标函数,越大,越适合
算法步骤
- 同
ID3
优缺点
- 缺点
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,
C4.5的剪枝方法有优化的空间。思路主要是两种,- 一种是预剪枝,即在生成决策树的时候就决定是否剪枝。
- 另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。
- 生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率
- 只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围
- 由于使用了熵模型,里面有大量的耗时的对数运算,这对有连续值且还有大量的排序运算时,耗时糟糕
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,
CART:只能二叉,三个算法中最优
改进的地方
- 使用
GINI系数,减少计算耗时 - 只能二叉,即每个特征只能分裂两个子节点
- 对于离散特征,如有多个类别,则不停二分,然后找出
GINI系数最小的那个分裂 - 对于连续特征,则按值从小到大排列,不断二分,找出
GINI系数最小的那个分裂
- 对于离散特征,如有多个类别,则不停二分,然后找出
分裂目标函数,越小,越适合
算法步骤
- 输入:
- $m$个样本,样本类别集合$D$,
- 特征集合$A$
gini系数的阈值,- 样本个数阈值
- 输出:
- 决策树$T$
- 过程
- 判断是否满足自然分裂条件:
- 判断样本是否为同一类别输出$L_i$,如果是则返回单节点树$T$。标记类别为$L_i$
- 判断特征是否为空,如果是则返回单节点树$T$。标记类别为样本类别集合$D$中实例数最多的类别
- 判断是否满足条件:
- 判断样本个数是否小于阈值,是则返回
- 计算特征集合$A$中的各个特征对$D$的
gini系数,选择值最小的特征$A_g$进行分裂- 对于离散、连续值分裂见改进的地方
- 对于缺失值,处理同
C4.5
- 如果$A_g$的
gini系数小于$\epsilon$,则返回单节点数$T$,标记类别为样本类别集合$D$中实例数最多的类别 - 否则,按分裂特征对应的样本类别$D$分成不同的类别集合$D_i$。每个类别产生一个子节点,对应特征值为$A_{gi}$。返回增加了节点的树$T$
- 对左右节点重复1-5步
- 得到树$T$
- 判断是否满足自然分裂条件:
CART回归树
如果样本输出是连续值,则是回归树
除了概念的不同,
CART回归树和分类树的建立和预测区别主要是:连续值的处理方法不同
- 分类树使用的是
gini系数,而回归树使用均方误差最小来进行特征分裂,公式如下
- 分类树使用的是
树建立后预测的方式不同
- 回归树使用叶子节点的均值来作为样本预测输出
剪枝
- 由于决策时算法很容易对训练集过拟合,而导致泛化能力差,为了解决这个问题,我们需要对CART树进行剪枝,
- 即类似于线性回归的正则化,来增加决策树的泛化能力
CART使用后剪枝
预剪枝
后剪枝
- 先生成决策树,然后产生所有可能的剪枝后的树
- 然后使用交叉验证来检验各种剪枝后的树的效果,选择泛化能力最好的树
- 剪枝步骤:
- 确定损失函数:$C_{\alpha}(T_t) = C(T_t) + \alpha |T_t|$
- $C(T_t)$:预测误差,回归树是均方误差,分类树是
GINI系数 - $\alpha$:正则化参数,越大剪枝越厉害
- $|T_t|$:叶子节点数量
- $C(T_t)$:预测误差,回归树是均方误差,分类树是
- 初始化$i=0,T=T_0$,最优子树集合$w=\{T\}$
- 从叶子节点自下而上的把所有节点是否剪枝的值$\alpha$计算出来
- 得到最小的$\alpha$以及对应的最优子树$T_i$
- 最优子树集合$w=w \cup T_i$
- 令$i=i+1,T=T_i$,重复2-5步
- 最后得到最优子树集合$w=\{T,T_0,T_1,…\}$
- 对最优子树集合的每一颗树去验证集预测,得到泛化能力最好的子树
- 确定损失函数:$C_{\alpha}(T_t) = C(T_t) + \alpha |T_t|$



