Introduction
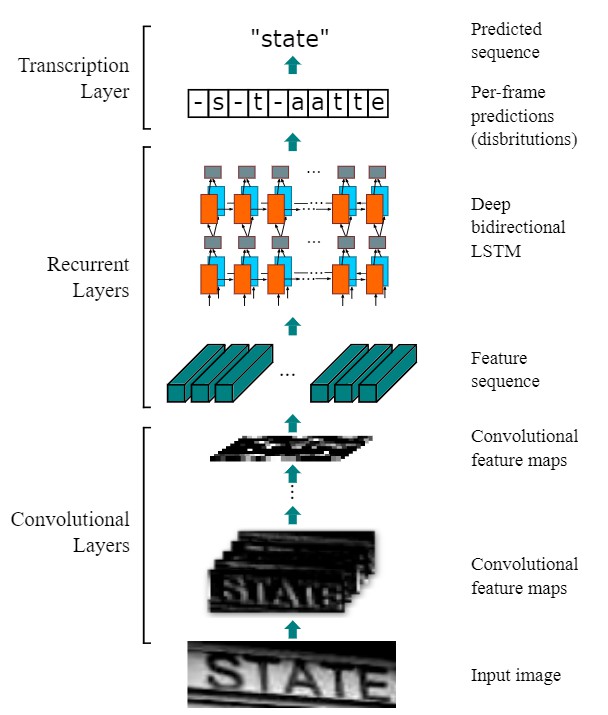
OCR
- OCR,光学字符识别,大家可能都用过,就是将图片中的文字提取出来形成文本
- 那在算法上如何做呢?如下图
- 首先是进行文字所在区域检测
- 然后识别检测到的区域


Related Works
text detection
DBNet(AAAI’2020): detail,速度准确性兼顾,支持弯曲文本检测。可微二值化的实时场景文本检测,使用FPN(特征金字塔)结构,在精度、效率上都表现优秀,支持弯曲文本检测,但是无法处理文本包含文本
@article{Liao_Wan_Yao_Chen_Bai_2020, title={Real-Time Scene Text Detection with Differentiable Binarization}, journal={Proceedings of the AAAI Conference on Artificial Intelligence}, author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang}, year={2020}, pages={11474-11481}}Mask R-CNN(ICCV’2017): detail,ResNet-FPN+Fast RCNN+mask。ResNet-FPN+Fast RCNN+mask(目标掩码),主要用于目标检测
@INPROCEEDINGS{8237584, author={K. {He} and G. {Gkioxari} and P. {Dollár} and R. {Girshick}}, booktitle={2017 IEEE International Conference on Computer Vision (ICCV)}, title={Mask R-CNN}, year={2017}, pages={2980-2988}, doi={10.1109/ICCV.2017.322}}PANet(ICCV’2019): detail, 像素聚合网络,速度快,任意形状文字。像素聚合网络,速度快,包含了两个步骤(1)用分割网络预测文字区域、核参数以及相似向量;(2)从预测的核中重建完整的文字实例
- 通过预测文字所处区域来描述文字的完整形状;
- 通过预测出核参数来区分不同的文字实例。
- 另外网络也会预测每个文字像素的相似向量,以保证像素的相似向量与来自同样文本的核之间的距离足够小
@inproceedings{WangXSZWLYS19, author={Wenhai Wang and Enze Xie and Xiaoge Song and Yuhang Zang and Wenjia Wang and Tong Lu and Gang Yu and Chunhua Shen}, title={Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network}, booktitle={ICCV}, pages={8439--8448}, year={2019} }PSENet(CVPR’2019): detail,预测多个分割结果,逐步扩张。这个文章主要做的创新点大概就是预测多个分割结果,分别是S1,S2,S3…Sn代表不同的等级面积的结果,S1最小,基本就是文本骨架,Sn最大。然后在后处理的过程中,先用最小的预测结果去区分文本,再逐步扩张成正常文本大小
@inproceedings{wang2019shape, title={Shape robust text detection with progressive scale expansion network}, author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={9336--9345}, year={2019} }TextSnake(ECCV’2018): detail,不规则文本预测,类似文本蛇。 该论文的创新点主要在于提出一个类似于文本蛇的检测方式对不规则文本进行预测,该算法主要做的是五个任务:1、预测文本 2、预测文本中心线 3、预测一个文本中15个圆的半径 4、预测中心线与圆心的sin 5、预测cos
@article{long2018textsnake, title={TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes}, author={Long, Shangbang and Ruan, Jiaqiang and Zhang, Wenjie and He, Xin and Wu, Wenhao and Yao, Cong}, booktitle={ECCV}, pages={20-36}, year={2018} }CRAFT(CVPR’2019): detail,速度快,弱监督做字符尺度的分割。文章最大贡献是它创新的提出了一种弱监督模型,可以在真实样本只有文本行标注的情况下,做字符尺度的图像分割
CTPN(ECCV’2016): detail,检测横向分布,字符级别。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字
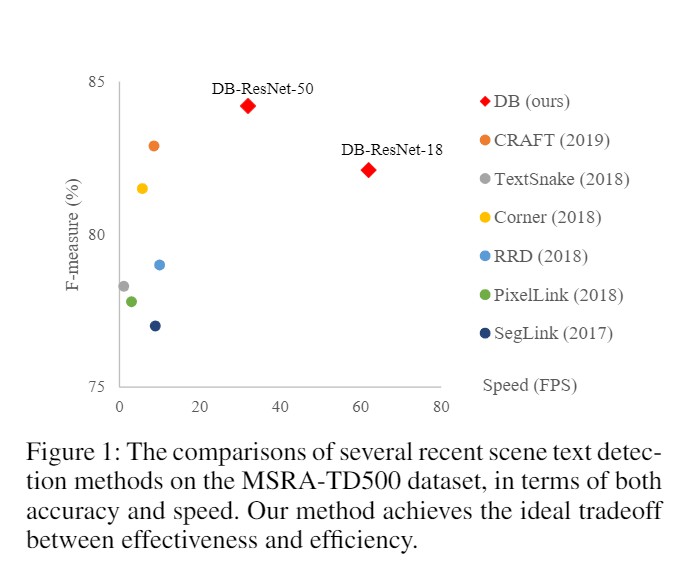
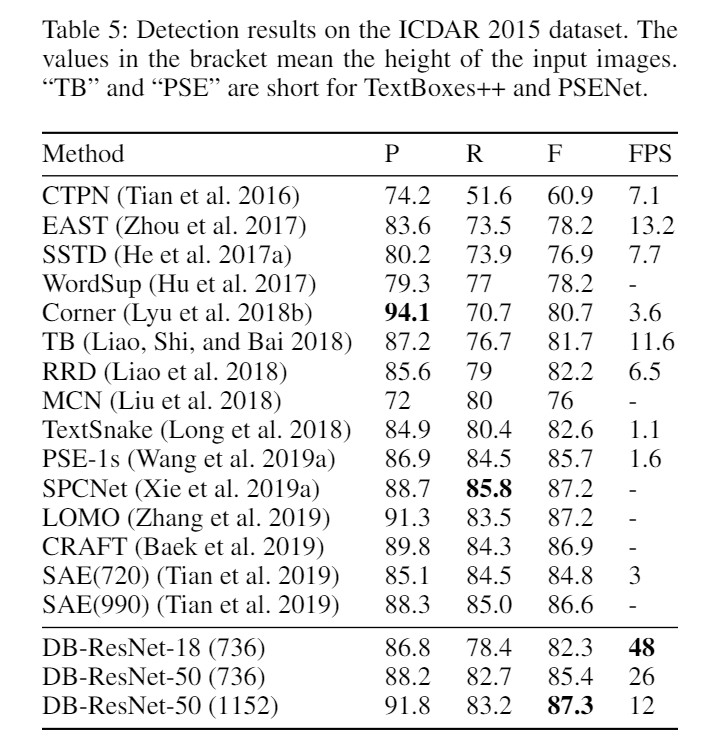
下面两张图来自DBNET论文,主要说明这些检测网络在公开数据集的表现,可以看出DBNET在这些检测网络中是速度与精度兼顾的。除了DBNET,PSENET和CRAFT的表现也还不错
text recognition
CRNN(TPAMI’2016): detail, CNN+RNN+CTC。卷积+循环神经网络+softmax即输出字符
@article{shi2016end, title={An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition}, author={Shi, Baoguang and Bai, Xiang and Yao, Cong}, journal={IEEE transactions on pattern analysis and machine intelligence}, year={2016} }NRTR(ICDAR’2019), A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition, 不使用CNN+RNN。注意力机制,本文首次提出了一种无重复序列到序列文本识别器,称为NRTR,它完全消除了重复和卷积。 NRTR遵循编码器-解码器范例,其中编码器使用堆叠式自注意提取图像特征,而解码器则应用堆叠式自注意来基于编码器输出识别文本。 NRTR完全依靠自我关注机制,因此可以以更高的并行度和更少的复杂性进行训练
@inproceedings{sheng2019nrtr, title={NRTR: A no-recurrence sequence-to-sequence model for scene text recognition}, author={Sheng, Fenfen and Chen, Zhineng and Xu, Bo}, booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)}, pages={781--786}, year={2019}, organization={IEEE} }RobustScanner(ECCV’2020): detail, 注意力机制,增加文本位置信息。 注意力机制,我们凭经验发现代表性的字符级序列解码器不仅利用上下文信息,而且利用位置信息。 现有方法高度依赖的文本信息会引起注意力漂移的问题。 为了抑制这种副作用,我们提出了一种新颖的位置增强分支,并将其输出与解码器关注模块的输出动态融合以进行场景文本识别
@inproceedings{yue2020robustscanner, title={RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition}, author={Yue, Xiaoyu and Kuang, Zhanghui and Lin, Chenhao and Sun, Hongbin and Zhang, Wayne}, booktitle={European Conference on Computer Vision}, year={2020} }SAR(AAAI’2019): detail,不规则文本识别,ResNet+LSTM+2-dimensional attention module。 由于文本外观的大变化(例如曲率,方向和变形),在自然场景图像中识别不规则文本非常困难。 现有的大多数方法都严重依赖复杂的模型设计和/或额外的细粒度注释,这在一定程度上增加了算法实现和数据收集的难度。 在这项工作中,我们使用现成的神经网络组件和仅单词级注释,为不规则场景文本识别提出了易于实施的强基准。 它由一个31层ResNet,一个基于LSTM的编码器-解码器框架和一个二维注意模块组成。 尽管它很简单,但是所提出的方法是健壮的。 它在不规则文本识别基准上达到了最先进的性能,并在常规文本数据集上实现了可比的结果
@inproceedings{li2019show, title={Show, attend and read: A simple and strong baseline for irregular text recognition}, author={Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu}, booktitle={Proceedings of the AAAI Conference on Artificial Intelligence}, volume={33}, number={01}, pages={8610--8617}, year={2019} }SegOCR Simple Baseline@unpublished{key, title={SegOCR Simple Baseline.}, author={}, note={Unpublished Manuscript}, year={2021} }
Experiments
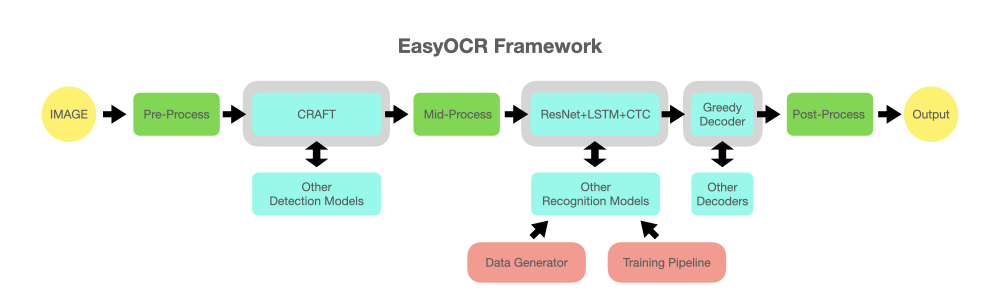
easyocr
结构如下图
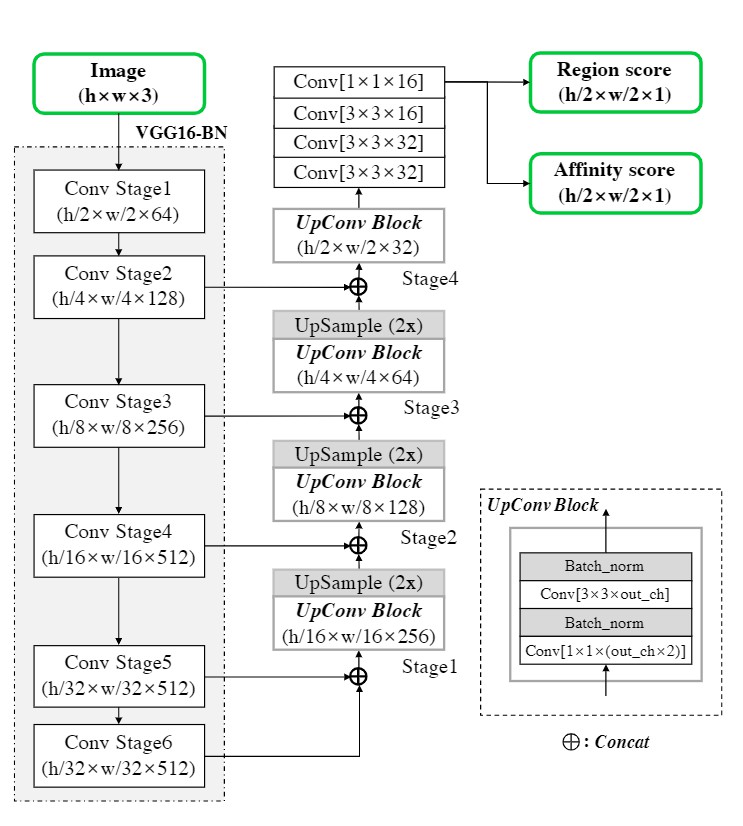
CRAFT网络结构
下图是它的网络结构,CRAFT的骨干卷积网络是VGG16,在此基础上作者使用了类似于U-net的结构,浅层和深层的卷积特征相结合作为输出,有效的保留了浅层的结构特征和深层的语义特征。在U-net之后,网络增加一系列层卷积操层,最终的1x1卷积层使用两个卷积核输出两个分支结果,第一支为各像素点处于字符中心的概率(位置分),第二支为各像素点处于字符间隙的概率(邻域分)。通过这两层输出,我们可以分别得到字符位置和字符间连接情况,进而将结果整合为文本框
CRAFT位置分邻域分标注
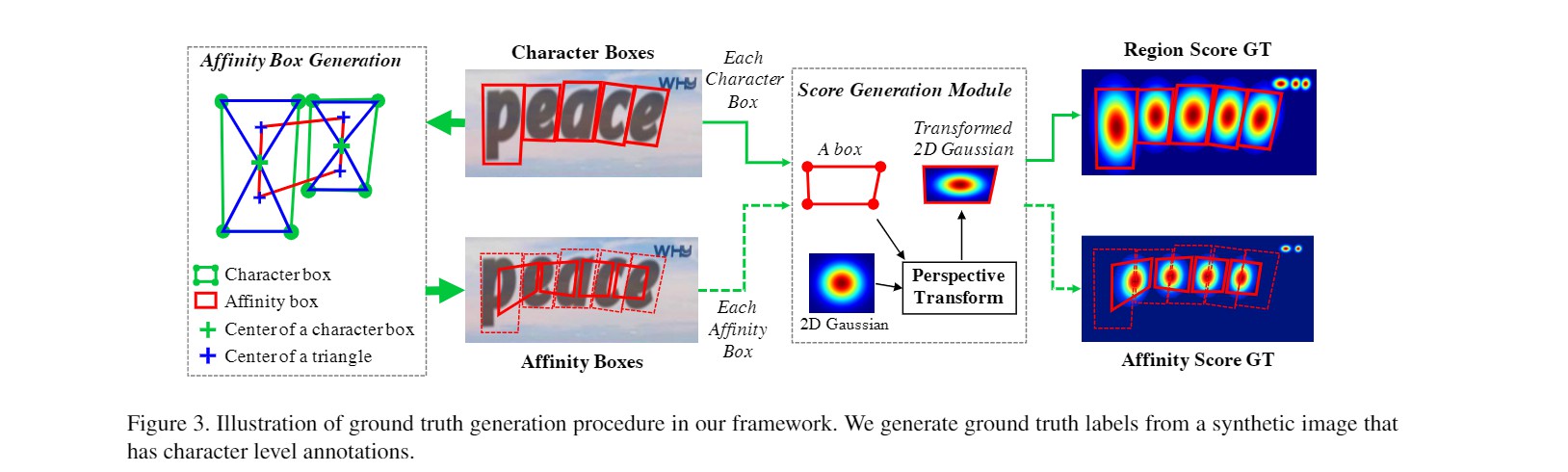
在CRAFT中,图像分割的标注是一个连续的二维高斯分布,位于字符框中心的像素点有较高的位置分,而位于字符框边缘的像素点位置分较低,从而模型充分利用了像素点的位置信息。由于字符框通常为不规则的四边形,具体操作中,CRAFT需将二维标准高斯分布变换到字符框四边形中,如下图
获取邻域分标注时,我们首先将字符框四边形的对角线相连,如上图左侧Affinity Box Generation中蓝色实线所示。接着,我们分别找到上下两个三角形的重心(蓝色十字),两个相邻的字符共有四个三角形重心,我们将它们组成的四边形定为邻域框。最后,我们用之前位置分相同的方法,生成邻域框内的高斯分布,从而得到了邻域分。最终的结果可见上图最右侧的heat map
CRAFT弱监督学习
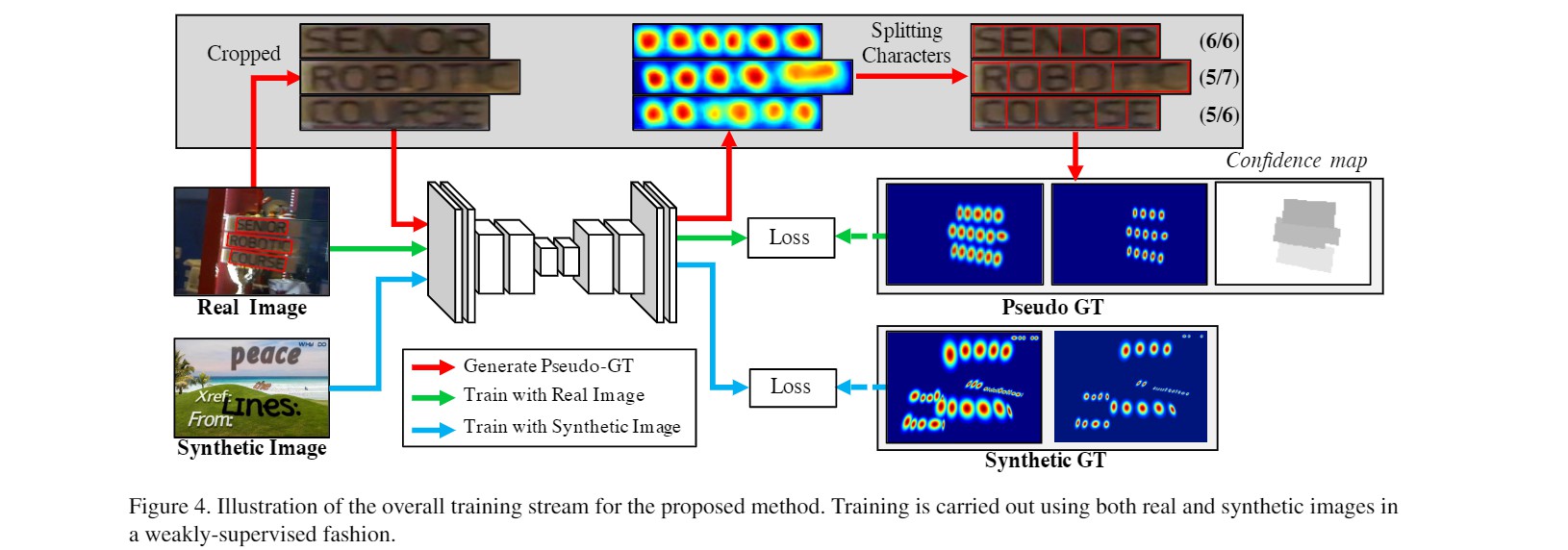
如何从文本框标注获得可靠的字符框标注是本文的最大亮点。CRAFT采用了弱监督学习的方法,有效的解决了这个问题。在训练初期,我们使用的训练集为合成的非真实图片,合成图片中具有字符框准确的标注信息,因而可以直接使用。合成图片与真实图片的数据特征有相似之处但又不完全相同,其可以为模型训练提供有限的帮助。当模型具有一定预测能力后,我们再开始使用真实图片。
由于真实图片缺乏字符框标注,文章中采取了以下的训练方案:首先我们将文本行截取出来,利用当前训练好的模型预测每个像素点的位置分;接着从位置分的分布中,我们可以分离出来当前模型判断的字符框数量和位置,并利用这些字符框作为标注回头来训练模型。由于此时模型预测的字符框准确性并没有保证,在计入损失函数时,我们需要为对应的损失乘以一个置信概率。需要注意的是,实际的字符数量(文本标注长度)是已知的,未知的仅仅是字符框的位置。因此,我们可以利用预测和实际的字符数量的差来衡量预测的准确性,即置信概率=1-字符数差/实际字符数量。例如下图中,三个文本行的置信概率分别为6/6,5/7和5/6。需要注意的是,为了保证这种训练模式的有效性,作者在这一步训练中也掺入了较低比例(1:5)的具有准确字符框标注的合成图片
CRAFT文本框生成
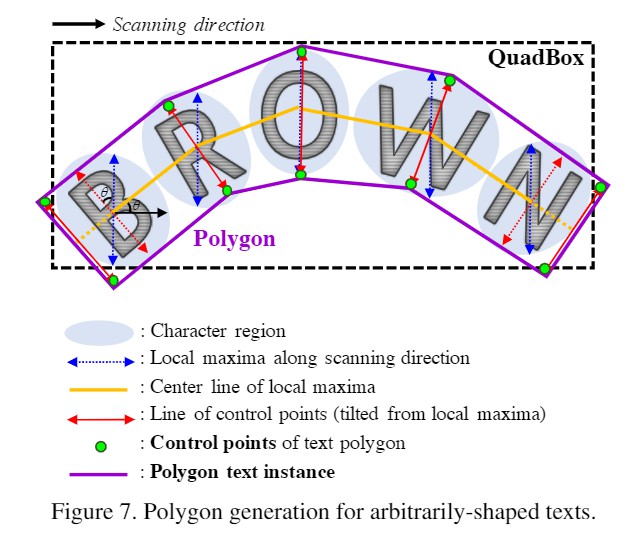
在得到了所有像素点的位置分和邻域分以后,我们还需要将结果整合为最终的文本框作为输出。文章中作者对位置分和邻域分分别设定了一个阈值,将两者中至少有一方高于阈值的像素点标为1,其他标为0,然后将所有相连的值为1的像素定为一个文本目标。在需要矩形文本框的任务中,我们找到一个面积最小的包围整个目标的矩形作为输出;在需要多边形文本框的任务中,我们可以根据每个字符的中心点和宽度构造一个多边形,如下图所示
第一步是沿扫描方向寻找特征区域的局部极大值线,蓝线,连接所有局部极大值中心点的线称为中心线,黄线,然后,旋转局部max-ima线,使其垂直于中心线,以反映字符的倾斜角度,红色箭头,局部极大值线的端点是文本多边形控制点的候选点
如何从文本框标注获得可靠的字符框标注是本文的最大亮点,感兴趣的童鞋可以点击detail
CRNN网络结构
cnstd+cnocr
PSENet网络结构
骨干网络:ResNet,预测多个分割结果,分别是$S1,…,Sn$,代表不同等级面积的结果,$S1$最小,基本就是文本骨架,$Sn$最大
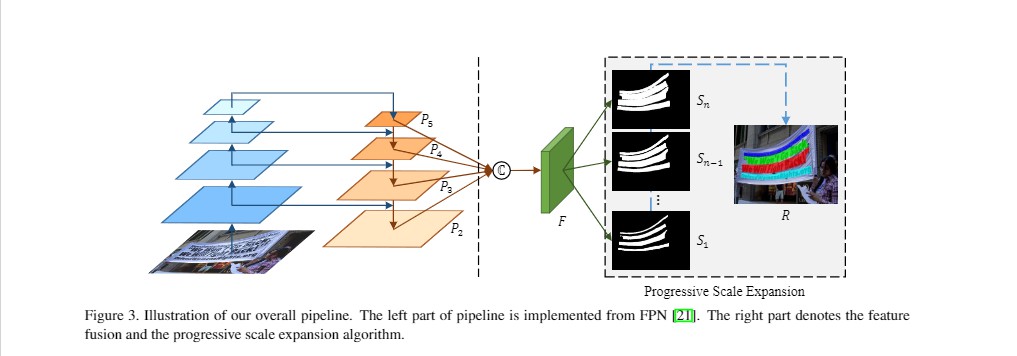
PSENet算法主体
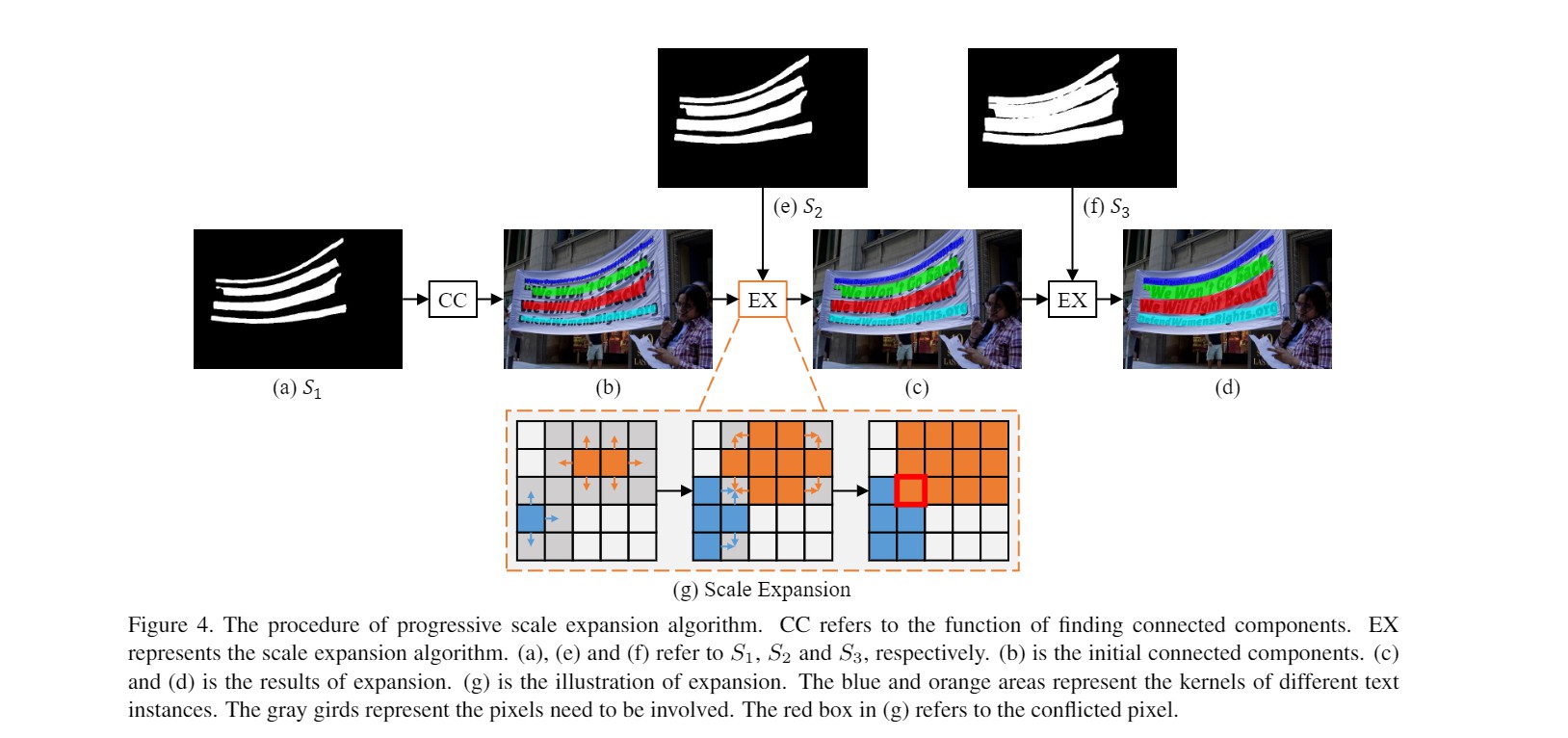
如下图所示:
- 网络有$S1,S2,S3$三个分割结果
- 先用最小的kernel生成的$S1$来区分四个文本实例
- 然后再逐步扩张成$S2,S3$
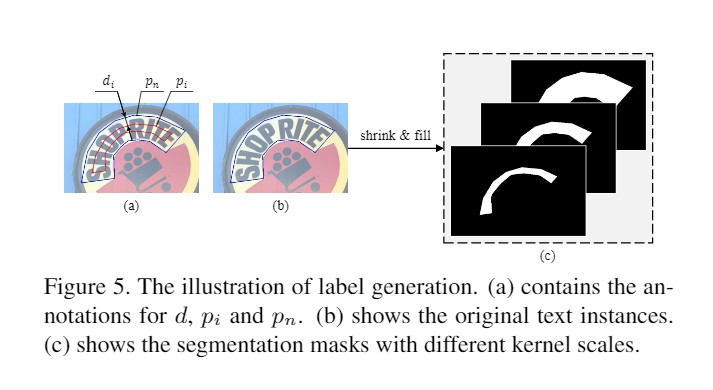
PSENet标注生成
- 根据已有多边形框标注计算
- $d_i=\frac{Area(p_n)\times (1-r_i^2)}{Perimeter(p_n)}$
- $r_i = 1-\frac{(1-m)\times (n-i)}{n-1}$
- $Area$: 面积
- $Perimeter$: 周长
- $r_i$: 缩放比例
CRNN网络结构
References
- [MMOCR Documents]: https://mmocr.readthedocs.io/en/latest/modelzoo.html
- 参考opencv实现视频切割
基础
视频截帧成一张张图片
使用opencv
# -*- coding:utf-8 _*-
"""
Author:
Email:
Date: 2021/03/12
File: opencv_test.py
Software: PyCharm
Description: 使用opencv将视频切成若干张静态图片(默认每秒1张)
"""
# load modules
import shutil
import time
import cv2
import os
import sys
# config类
class Config:
Maps = {
# 以下请根据需要调整数值
"split_duration": 1.5, # 切片间隔,每 split_duration 秒输出一帧
"jpg_quality": 40, # 图片输出质量, 0~100
"probability": 0.66, # OCR可信度下限, 0~1
"subtitle_top_rate": 0.66, # 字幕范围倍率
"remove_duplicate": False, # 强制去重
# 目录信息,在下方定义
"video_dir": "",
"video_path": "",
"video_frames": "",
"image_dir": "",
"output_dir": "",
# 视频信息,自动生成
"video_name": "",
"video_suffix": "",
"video_width": 0,
"video_height": 0,
"subtitle_top": 0, # 字幕范围 = 字幕范围倍率 * 视频高度,此高度以下的文字被认为是字幕
}
@staticmethod
def set_path(video_name="", video_suffix=""):
current_path = sys.path[0]
Config.Maps["video_dir"] = '%s/video/' % current_path # 视频源文件目录
Config.Maps["video_path"] = '%s/video/%s%s' % (current_path, video_name, video_suffix) # 指定视频文件路径
Config.Maps["video_frames"] = '%s/video_frames/' % current_path # 视频切片文件目录
Config.Maps["image_dir"] = '%s/video_frames/%s/' % (current_path, video_name) # 指定视频切片文件目录
Config.Maps["output_dir"] = '%s/output/' % current_path # 字幕输出目录
Config.Maps["video_name"] = video_name
Config.Maps["video_suffix"] = video_suffix
@staticmethod
def set_video_props(video_width, video_height):
Config.Maps["video_width"] = video_width
Config.Maps["video_height"] = video_height
Config.Maps["subtitle_top"] = Config.Maps["subtitle_top_rate"] * video_height
@staticmethod
def get_value(key):
return Config.Maps[key]
# getFrame类
class GetFrames:
@staticmethod
def main():
# 读取路径信息
video_path = Config.get_value("video_path")
image_dir = Config.get_value('image_dir')
jpg_quality = Config.get_value('jpg_quality')
split_duration = Config.get_value('split_duration')
if (os.path.exists(image_dir)):
shutil.rmtree(image_dir) # 递归删除目录,os.rmdir只能删除空目录
os.mkdir(image_dir)
cv = cv2.VideoCapture(video_path) # 读入视频文件
current_frame = 1
saved_frames = 1
if cv.isOpened(): # 判断是否正常打开
retval, frame = cv.read()
else:
cv.release()
print("Video open error")
return False
duration = int(cv.get(cv2.CAP_PROP_FPS) * split_duration) # 间隔频率 = 帧率 * 切片时间间隔(四舍五入)
frame_count = int(cv.get(cv2.CAP_PROP_FRAME_COUNT)) # 视频总帧数
video_width = int(cv.get(cv2.CAP_PROP_FRAME_WIDTH)) # 视频宽度
video_height = int(cv.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 视频高度
Config.set_video_props(video_width, video_height)
while retval: # 循环读取视频帧
retval, frame = cv.read()
if current_frame % duration == 0: # 每 duration 帧进行存储操作
cv2.imencode('.jpg', frame, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality])[1]. \
tofile(image_dir + str(current_frame).zfill(6) + '.jpg')
print(("Now: frame %d, saved: %d frame(s), process: %d%%" %
(current_frame, saved_frames, (current_frame * 100) // frame_count)).ljust(60, ' '))
saved_frames += 1
current_frame += 1
cv2.waitKey(1)
print(("Now: frame %d, saved: %d frame(s), process: %d%%" %
(current_frame, saved_frames, (current_frame * 100) // frame_count)).ljust(60, ' '))
cv.release()
print("\nSaved: %d frame(s)" % saved_frames)
return True
# 主类
class Main:
@staticmethod
def clear():
if sys.platform.find("win") > -1:
os.system("cls")
else:
print()
@staticmethod
def main():
# 配置路径
Config.set_path()
if not (os.path.exists(Config.get_value('video_dir'))):
os.mkdir(Config.get_value('video_dir'))
if not (os.path.exists(Config.get_value('video_frames'))):
os.mkdir(Config.get_value('video_frames'))
if not (os.path.exists(Config.get_value('output_dir'))):
os.mkdir(Config.get_value('output_dir'))
# 列出所有video
Main.clear()
print("\n")
print("-"*40)
print("List Video")
print("-" * 40)
video_list = os.listdir(Config.get_value('video_dir'))
print(video_list)
if len(video_list) < 1:
print("Nothing found\n\n")
print("Process finished")
input()
return
# 对所有video进行处理
start_all = time.time()
print("\n")
print("-" * 40)
print("All Video Division")
print("-" * 40)
print("Start All video division")
for video in video_list:
print("%d.%s" % (video_list.index(video) + 1, video))
video_name = video[: video.rfind(".")]
video_suffix = video[video.rfind("."):]
Config.set_path(video_name, video_suffix)
start = time.time()
print("\n")
print("-" * 40)
print("Video: %s Division" % video)
print("-" * 40)
print("Start video division")
if not GetFrames.main():
print("Video division FAILED!")
print("Process finished")
input()
return
print("Video: %s division finished" % video)
print("Time: %.2fs\n" % (time.time() - start))
print("All Video division finished")
print("Time: %.2fs\n" % (time.time() - start_all))
return
if __name__ == "__main__":
Main.main()
进阶
疑难
参考
- opencv实现视频切割
- FFmpeg视频处理
- darknet-ocr:
star:851 - chineseocr:
star:3.9k - https://github.com/ouyanghuiyu/chineseocr_litegithub.com:
star:6.4k,支持windows - 包括AlexNet、RCNN、ResNet、YOLO、SSD等。
- 文本检测的资源汇总
- xiaofengshi:chinese-ocr:
star:2.4k - 场景文字检测—CTPN原理与实现
- 一文读懂CRNN+CTC文字识别
- 视频标签算法解析
- text-detection:文字识别相关topic
- 多模态研究综述
- easyocr
- 解码器:链接
- github ocr topics 排行榜



