基础
问题
- 如何对一篇文章的关键词进行提取
解决
- 使用类似网页排名算法
PageRank的思路 - 构建词与词之间的图,然后迭代计算词的排名
TextRank
- 回顾
PageRank的计算公式:$P=(1-d)\frac{I}{n}+dA^TP$ - 直接说
TextRank的计算公式:$P=(1-d)\frac{I}{n}+dW^TP$- 其中$W=(w_{ij})_{m\times n}$为词与词之间的权重,一般为词$i$与词$j$在滑动窗口$k$内的共现次数
如何根据词构建图
对文章$S$进行分词,得到词列表
设定滑动窗口$k$的大小,统计滑动窗口内各词对的贡献次数
例如:
淡黄的长裙,蓬松的头发,分词后为[淡黄,长裙,蓬松,头发]设定滑动窗口$k=2$,则得到词对:
淡黄,长裙长裙,蓬松蓬松,头发
根据这些词对构建
无向图,注意PageRank是有向图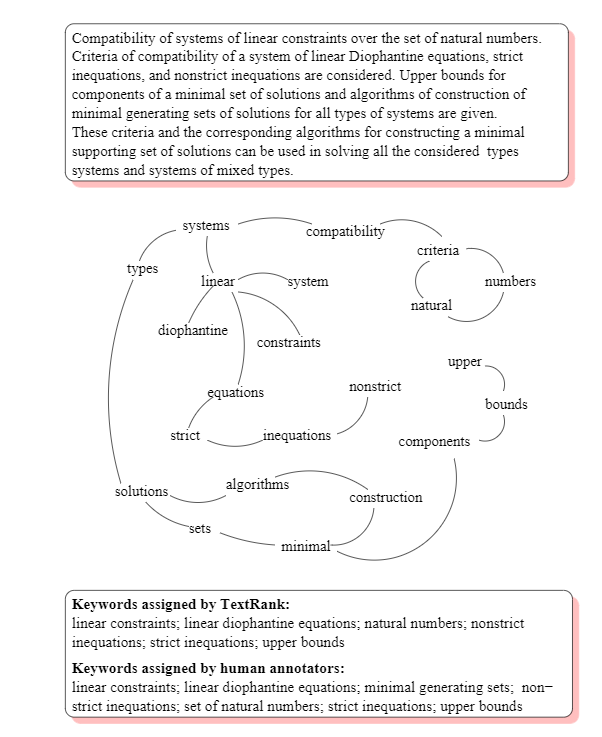
然后使用公式计算
进阶
疑难
实现
-
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))



