基础
分词的基本原理
基于统计的分词,统计的样本内容来自一些标准的语料库
举个栗子,我们分词的时候希望~小爱/来到/天河/区~这个分词后句子出现的概率要比~小爱/来到/天/河/区~的大
上述例子用数学语言表示如下
如果有一个句子
S,它有m中分词选项如下:其中$n_i$代表第$i$种分词的词个数,我们希望从中选出的是:$r = \underbrace{arg\;max}_iP(A_{i1},A_{i2},…,A_{in_i})$
但是$P(A_{i1},A_{i2},…,A_{in_i})$不好求,故使用马尔可夫假设,假设当前词只与其前一个词有关,则:$P(A_{i1},A_{i2},…,A_{in_i}) = P(A_{i1})P(A_{i2}|A_{i1})P(A_{i3}|A_{i2})…P(A_{in_i}|A_{i(n_i-1)})$
通过标准语料库,可以近似计算所有分词的二元条件概率,即:
N元模型实际应用中会出现一些问题:- 某些生僻词,或者相邻分词联合分布在语料库中没有,概率为0。这种情况我们一般会使用拉普拉斯平滑,即给它一个较小的概率值
- 第二个问题是如果句子长,分词有很多情况,计算量也非常大,这时我们可以用下一节==维特比算法==来优化算法时间复杂度。
N元模型即假设当前词与其前N个词相关
使用维特比算法分词
举个栗子
输入:
S=~人生如梦境~,它在语料库中可能的概率图如下: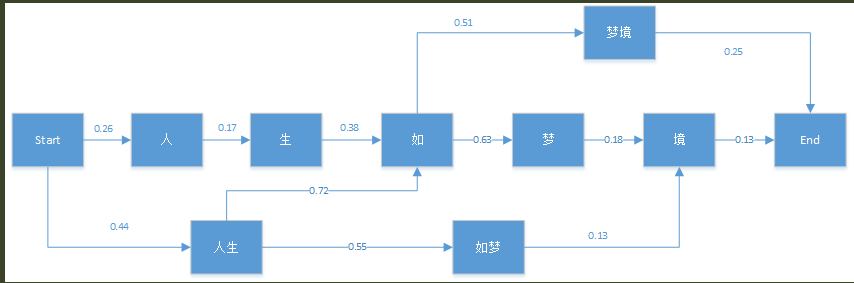
使用维特比算法如下:
首先初始化有:$\delta(人) = 0.26\;\;\Psi(人)=Start\;\;\delta(人生) = 0.44\;\;\Psi(人生)=Start$
对节点
生:$\delta(生) = \delta(人)P(生|人) = 0.0442 \;\; \Psi(生)=人$对节点
如:$\delta(如) = max\{\delta(生)P(如|生),\delta(人生)P(如|人生)\} = max\{0.01680, 0.3168\} = 0.3168 \;\; \Psi(如) = 人生$其他节点类似如下:
从而最终分词结果为~人生/如/梦境~
进阶
疑难
常用中文分词工具
- Jieba:
star:25.7k做最好的 Python 中文分词组件 - SnowNLP:
star:5.3kSimplified Chinese Text Processing - pkuseg:
star:5.3k一个多领域中文分词工具包 - THULAC:
star:1.5k一个高效的中文词法分析工具包 - 其他:详情请见



