基础
简介
Storm是什么?
- Storm是Apache下的一个分布式实时大数据处理系统
Storm优势
- 实时流
- 快
- 数据处理保证
- 容错
概念
组件
Tuple
- 主要数据结构,有序元素的列表
- 默认情况支持所有数据类型
- 通常是一组逗号分隔的值
Stream
- Tuple的无序序列
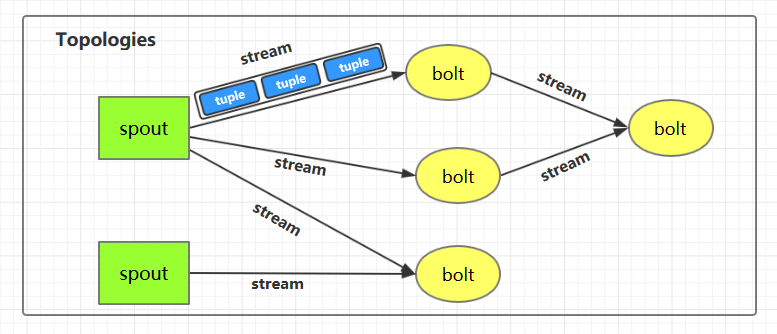
Spouts
- Stream的源头
- 通常,Storm从原始数据源(Kafka队列等)接受数据
- 也可以通过编写Spouts从数据源读取数据
- “ISpout”是实现Spout的核心接口
- 一些特定的接口包括:IRichSpout,BaseRichSpout,KafkaSpout等
Bolts
- 逻辑处理单元
- 可以执行过滤、聚合等数据操作
- “IBolt”是实现Bolt的核心接口
- 一些特定的接口包括:IRichBolt,IBasicBolt等
拓扑
- 图:storm拓扑就是一个拓扑
- Spouts和Bolts连接就形成拓扑结构
- 拓扑是有向图,顶点是计算,边是数据流
- Storm始终保持拓扑运行直到你终止且主要工作就是运行拓扑
任务
- Storm执行的每个Spout和Bolt被称为任务
进程
- 一个拓扑中的顶点被分布到多个工作节点上分布式运行
- Storm将所有工作节点上的任务均匀分布
- 工作节点的角色是监听作业,并在新作业到达时启动或停止进程
流分组
数据流从Spouts流到Bolts,或从一个Bolts流到另一个Bolts时,则需要分组控制,有以下四种分组方式
随机分组
- 相等数量的Tuples随机分布在执行Bolts的所有worker(包含工作节点和工作节点进程)中
字段分组
- Tuples中具有相同字段的分配给同一个worker
全局分组
- 所有Tuples分配给同一个worker
所有分组
- 将所有Tuples都建立副本,并分配给所有的worker
集群架构
架构图
组件
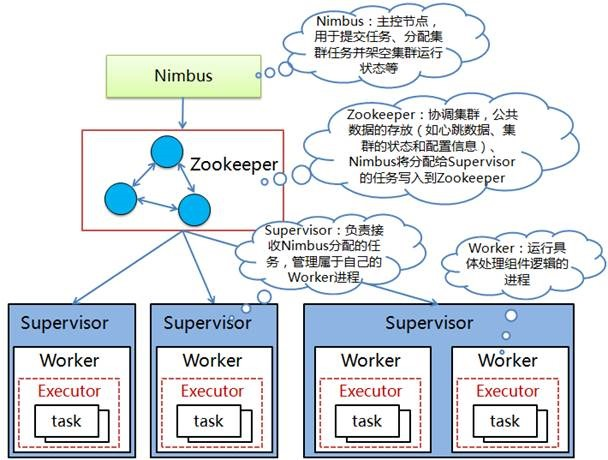
Nimbus(主节点)
- 集群的主节点
- 负责给工作节点分发任务和数据
- 监听各工作节点的故障
Supervisor(工作节点)
- 除了主节点的其他节点
- 完成主节点分配任务的节点
- 至少有一个工作进程
Worker process(工作进程)
- 执行与特点拓扑相关的任务
- 不会自己运行任务
- 通过创建执行器Executor来执行特点的任务
- 拥有多个执行器Executor
Executor(执行器)
- 工作进程产生的单个线程
- 至少运行一个任务
- 仅用于特定的Spout或Bolt
Task(任务)
- 处理实际的数据
- 要么是Spout,要么是Bolt
ZooKeeper
- Nimbus是无状态的,所以需要ZooKeeper来监视工作节点的状态
- 通过ZooKeeper来监视状态,这样故障的网络就可以重新启动
工作流程
流程图
详细流程介绍
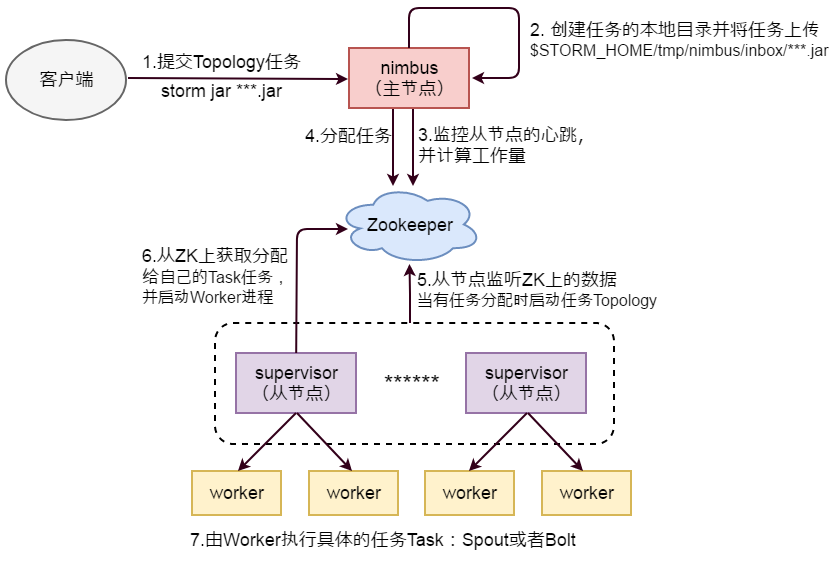
- Nimbus等待客户端提交拓扑任务
- Nimbus创建任务的本地目录并将任务上传至
$STORM_HOME/tmp/nimbus/inbox/ - Nimbus从ZooKeeper监控工作节点的心跳并计算拓扑的工作量
- Nimbus将任务分配信息写入ZooKeeper
- 工作节点监听ZooKeeper的信息,当有任务分配时,启动任务的拓扑
- 工作节点启动任务拓扑后,启动相应数目的worker进程
- 由worker进程来执行任务(Spout或Bolt)
分布式消息系统
Kafka
- 详情请见



