发布日期:
2019-11-27
文章字数:
1.5k
阅读时长:
5 分
阅读次数:

HDFS基础
分布式文件系统
- 分布式文件系统把文件分布存储在多个计算机节点上,成千上万的计算机节点构成计算机集群
HDFS简介与相关概念
HDFS简介
实现目标:
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
局限
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
相关概念
块
- HDFS默认一个块64MB,一个文件被分成多个块,以块为存储单位
- 块的大小远远大于普通文件系统,可以最小化寻址开销
- 块带来的好处:
- 支持大规模文件存储:一个大规模文件可以分成若干个块,不同的块分发到不同的节点上
- 简化系统设计:大大简化了存储管理以及方便了元数据的管理,元数据管理可以由其他系统负责
- 适合数据备份:采用冗余存储到多个节点,提高容错性和可用性
NameNode
功能:
- 存储元数据
- 元数据保存到内存中
- 保存文件,block,DataNode之间的映射关系
数据结构
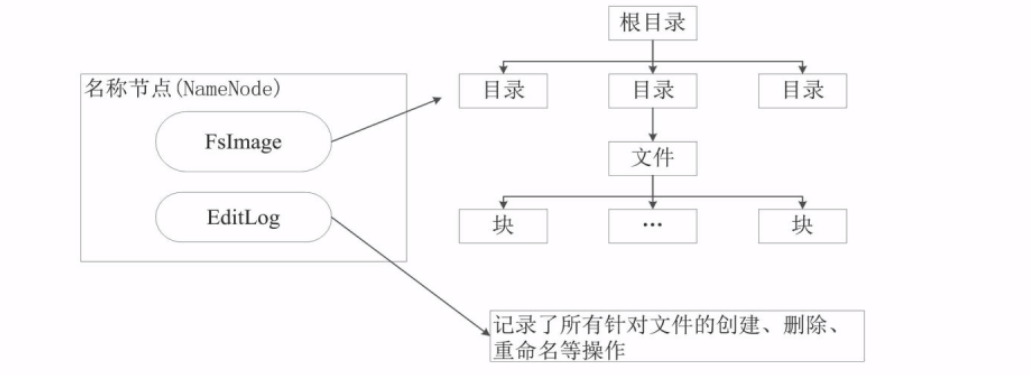
- FsImage:维护系统文件树以及所有元数据,包含文件的复制等级、修改、访问时间、访问权限、块大小以及组成文件的块,目录的存储修改时间、权限和配额。没有记录块存储在哪个DataNode,而是存储映射关系到内存。每次增加DataNode到集群时,DataNode都会把自己包含的块列表告知NameNode,确保映射是最新
- EditLog:记录创建、删除、重命名等操作
启动
- 启动的时候,将FsImage文件中的内容加载到内存,再执行EditLog中的各项操作,使得内存中的元数据和实际的同步
- 一旦内存中成功建立文件系统元数据的映射,则创建一个新的FsImage和一个空的EditLog
- 每次执行写操作之后,且在向客户端发送代码之前,EditLog都需要同步更新
- 因为FsImage文件一般很大(GB常见),如果所有的更新操作都往里加,则会导致系统变慢,所以需要一个不断更新的EditLog
- 但是随着对文件不断的更新,EditLog也会不断的增大,怎么解决这个问题呢?使用SecondaryNameNode,详情如下:
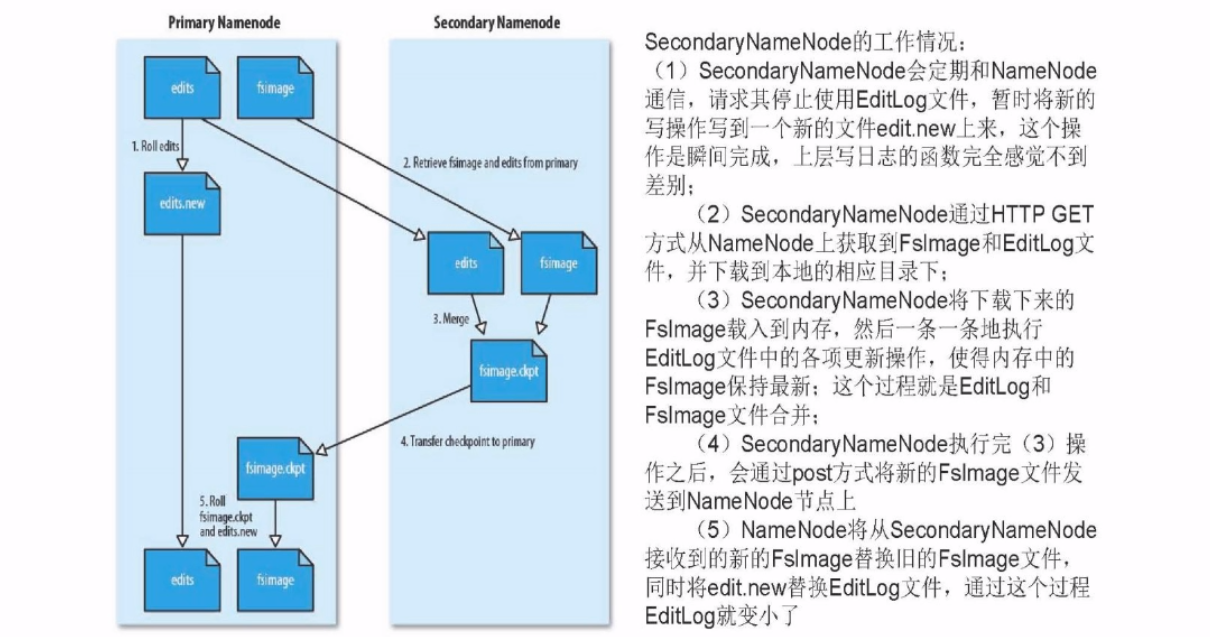
内存全景
DatanNode(廉价机器)
功能
- 存储文件内容
- 文件内容保存到磁盘
- 维护block id到DataNode本地文件的映射关系
HDFS结构
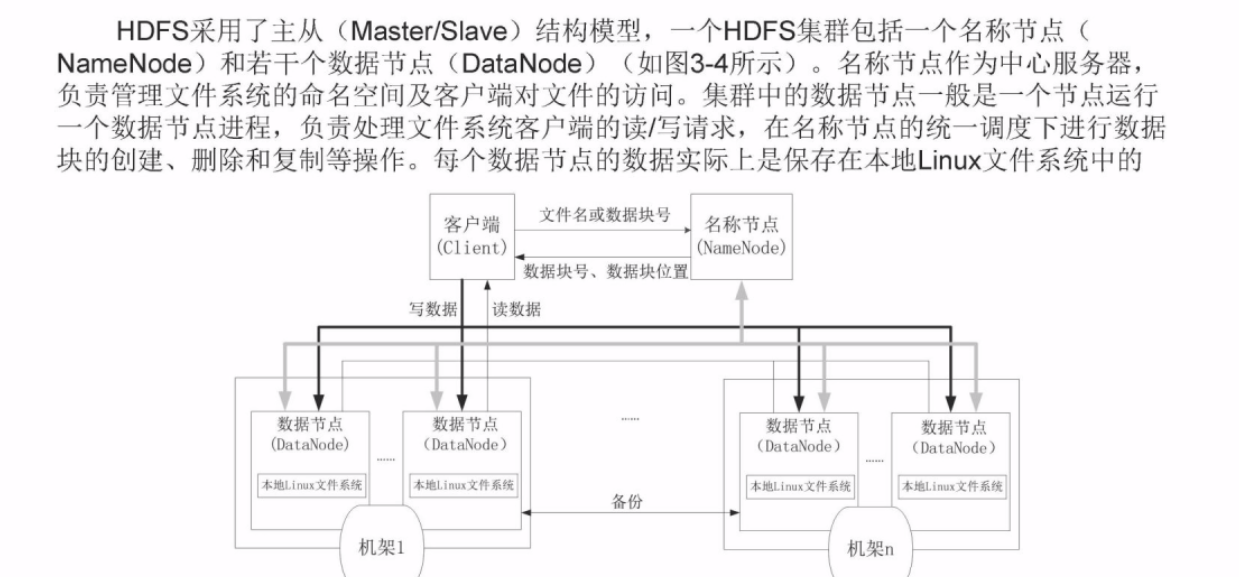
HDFS命名空间管理
- 命名空间包含目录、文件和块
- 使用的是传统的分级文件体系
通信协议
- 在TCP/TP协议之上
- 客户端通过一个可配置的端口向NameNode主动发起TCP连接,并使用客户端协议与NameNode进行交互
- NameNode与DataNode之间使用数据节点协议交互
- 客户端与DataNode使用RPC(remote procedure call)实现
客户端
- HDFS在部署时提供了客户端
- 客户端是一个库,暴露HDFS文件系统接口
- 客户端支持打开、读取、写入等常见操作,提供类shell的命令行访问数据
HDFS-1.0-局限性
- 命名空间的限制:NameNode保存在内存中,受到内存空间大小限制
- 性能的瓶颈:受限单个NameNode的吞吐量
- 隔离问题:集群中只有一个NameNode,只有一个命名空间,因此没法对不同程序进行隔离
- 集群的可用性:一旦唯一的NameNode发生故障,则导致整个集群不可用
HDFS存储原理
冗余数据保存
- 多副本对数据进行冗余保存,一般默认冗余保存3份
- 优点
- 加快数据传输速度
- 容易检查数据错误
- 保证数据可靠性
数据存取策略
数据存放
- 第一个副本:放置在上传文件的数据节点;如果在集群外提交,则随机挑选机器存放
- 第二个副本:放置在与第一个副本不同的机架(rack)的节点上
- 第三个副本:与第一个副本相同机架的不同节点上
数据读取
- 当客户端读取数据时,从NameNode获得数据块不同副本的存放位置列表,通过API来获取这些存放位置的机架ID与客户端对应机架ID,如果ID相同,则优先选择该副本,反之随机读取
数据错误与恢复
NameNode出错
- 使用SecondaryNameNode进行数据恢复
DataNode出错
- 心跳机制:每个DataNode会定期向NameNode发送心跳信息
- 当DataNode出错时,NameNode收不到心跳,则会将他们标记为“宕机”,其节点上所有数据标记为“不可读”,也不会再给他们发送任何IO请求
- NameNode还会检查,当某个数据库的副本数量小于冗余因子,就会启动数据冗余复制,产生新副本
数据出错
- 网络传输和磁盘错误等因素,会造成数据错误
- 当文件本创建时,客户端会对每一个文件进行信息摘录,并写入到同一路径的隐藏文件中
- 当客户端读取文件的时候,会先读取信息摘录文件,然后对读取的数据块进行校验,如果检验出错,客户端则会请求到另外一个DataNode读取文件块,并向NameNode报告这个文件块有错误,然后NameNode会重新复制这个块
HDFS数据读写过程
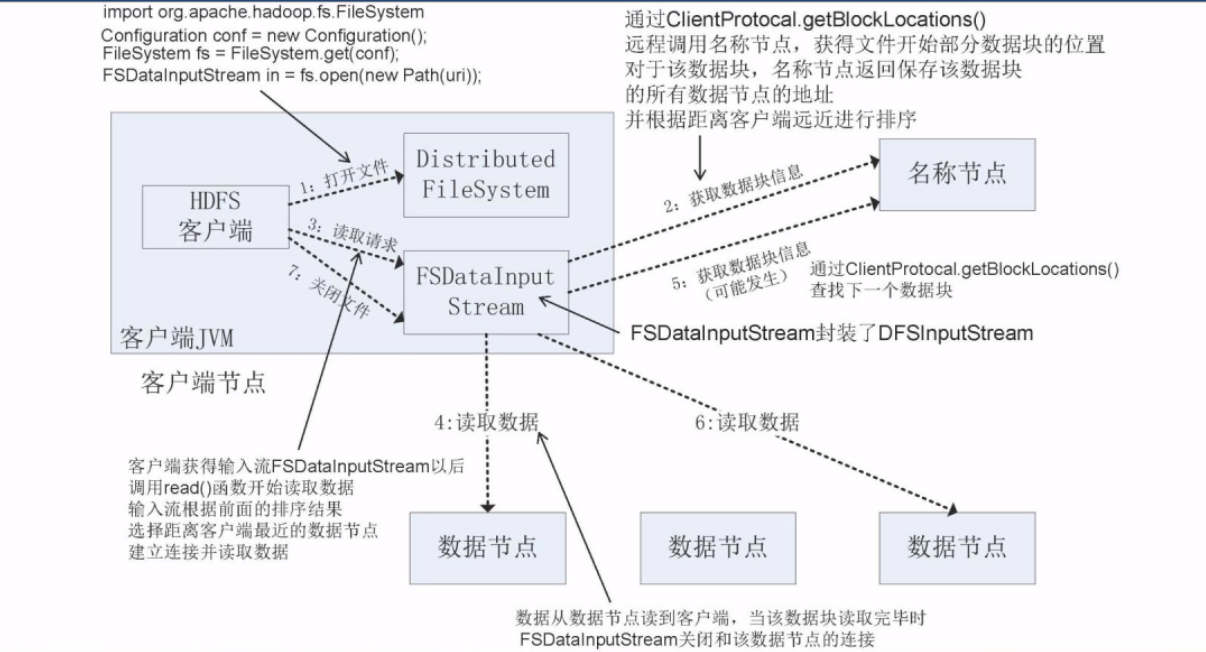
读过程-JAVA
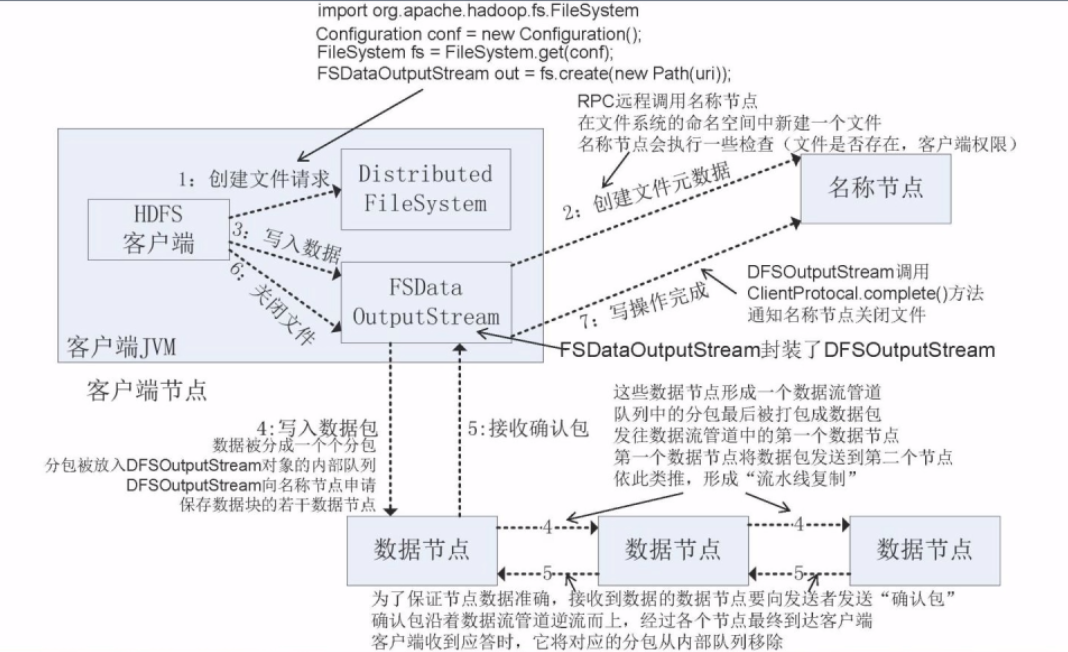
写过程-JAVA
HDFS进阶
HDFS编程实践
参考书籍
疑难解答



