
Hadoop介绍
第一部分-简介
简介
- Hadoop是apache下的一个开源分布式计算平台
- 基于Java开发,跨平台特性好(其他编程语言也可以使用),可以部署再廉价的计算机集群中
- 核心是HDFS(分布式文件系统)和MapReduce
特性
- 高可靠性:冗余副本和容错机制
- 高效性:把成百上千的服务器集中起来做分布式处理
- 高可扩展性:几个到上千个节点
- 高容错性:冗余副本和容错机制
- 成本低:整个机器集群可以是很多低端机
- 运行在Linux平台上:原生是Linux
- 支持多种编程语言:基于Java开发,但还可以多种语言开发
第二部分-结构
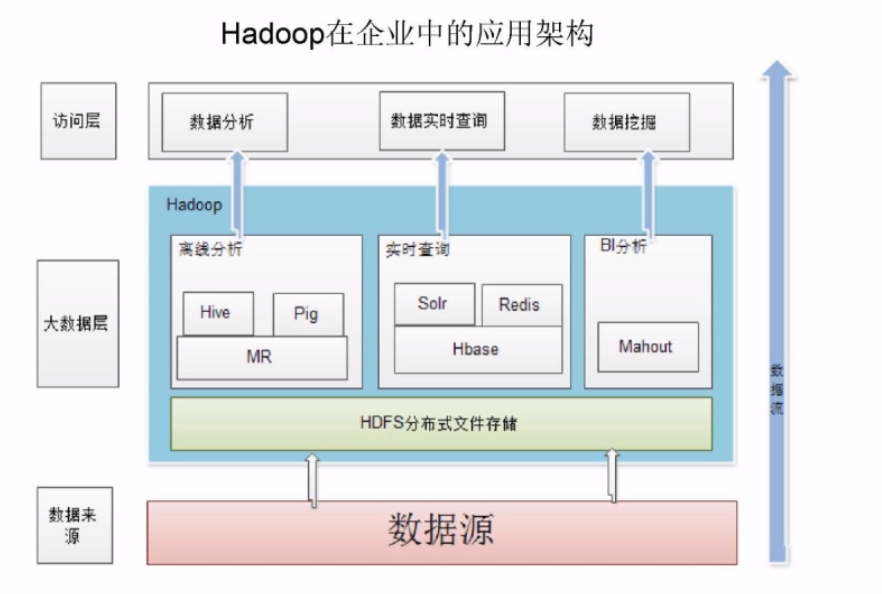
企业应用架构
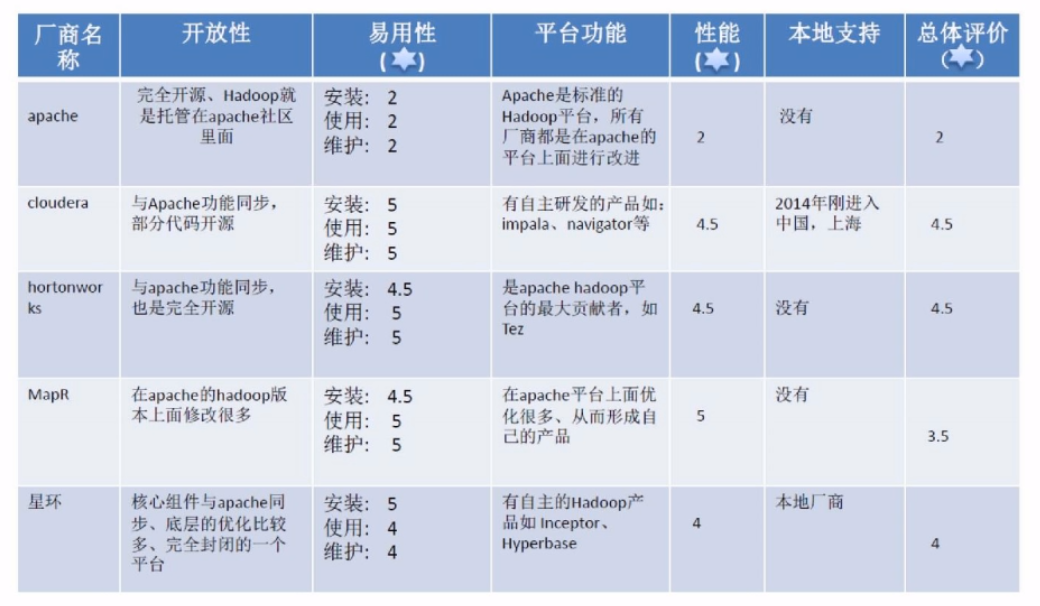
各种版本
项目结构
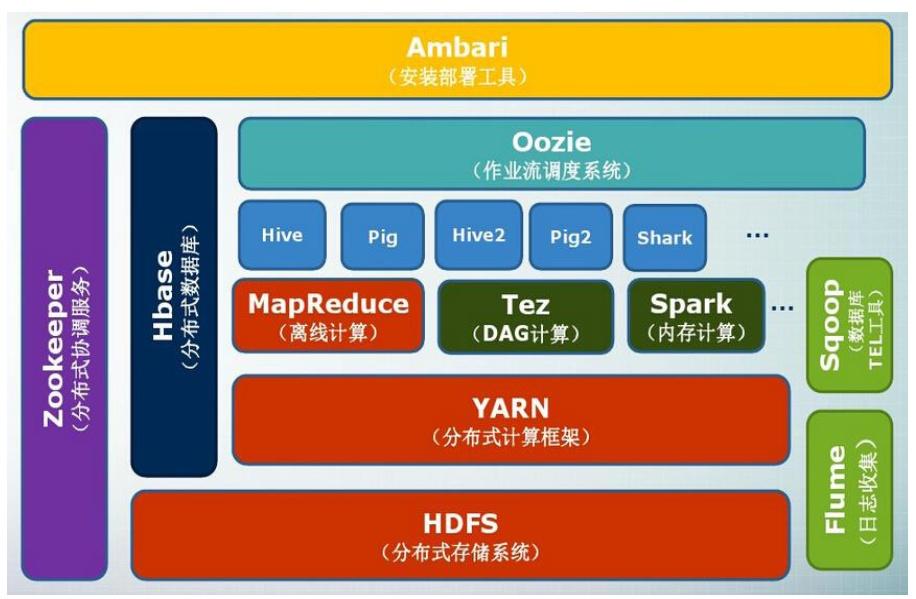
- 分布式存储系统-HDFS:怎么用成百上千的机器去存储文件,详情请见
- 分布式计算框架-YARN:负责计算资源调度,内存、CPU、带宽等等
- 离线计算-MapReduce:分布式并行编程模型,离线计算、批处理,基于磁盘,详情请见
- DAG计算-Tez:运行在YARN之上的下一代Hadoop查询处理框架,将很多的MapReduce作业进行分析优化以后构建成一个有向无环图(DAG),保证获得最好的处理效率,详情请见
- 内存计算-Spark:类似MapReduce的通用并行框架,基于内存计算,性能比MapReduce高,详情请见
- Hive:Hadoop上的数据仓库,把大量的历史数据保存到数据仓库中,建立各种维度,专门用于企业决策分析,支持SQL语句,会将SQL语句转化为MapReduce作业去执行,详情请见
- Pig:基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin,流数据处理,轻量级分析,用一两行语句就可以跟复杂的MapReduce语句得到一样的结果,详情请见
- 作业流调度系统-Oozie:把很多个工作环节进行调度,详情请见
- 分布式协调服务-ZooKeeper:提供分布式协调一致性服务,分布式锁,集群管理等操作,详情请见
- 分布式数据库-HBase:Hadoop上的非关系型分布式数据库,基于列的存储,随机读写,支持实时应用,详情请见
- 日志收集-Flume:高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,详情请见
- 数据库TEL工具-Sqoop:用于在Hadoop与传统数据库之间的数据传递,完成数据导入导出,详情请见
- 安装部署工具-Ambari:快速部署工具,支持Hadoop集群的供应、管理和监控,详情请见
第三部分-本机安装
apache Hadoop安装与使用
Hadoop三种shell命令的区别
- hadoop fs 适用于任何不同的文件系统
- hadoop dfs 只能适用于HDFS文件系统
- hdfs dfs 只能适用于HDFS文件系统
第四部分-集群部署
集群节点类型及硬件配置
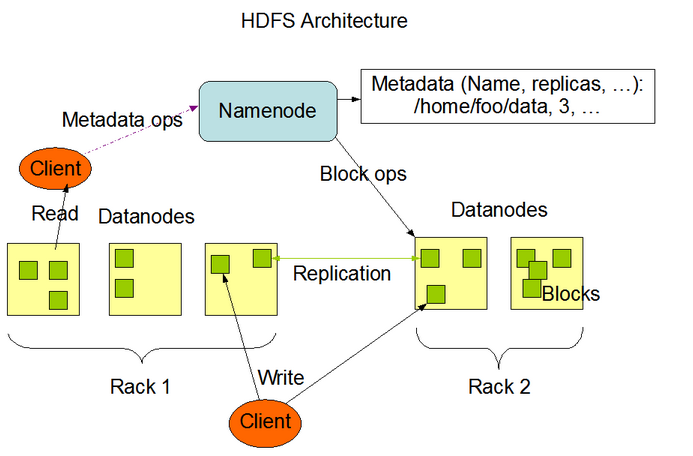
- NameNode:负责协调集群中的数据存储,获得数据的地址信息,哪块在哪个机器这样子(HDFS节点)
- DataNode:存储被拆分的数据块(HDFS节点)
- JobTracker:协调数据计算任务(MapReduce节点)
- TaskTracker:负责执行由JobTracker指派的任务(MapReduce节点)
- SecondaryNameNode(冷备份):帮助NameNode收集文件系统运行的状态信息(HDFS节点)
集群规模可大可小,可以一步一步往上加机器。
在集群中,大部分的机器是作为DataNode和TaskTracker工作的,所以DataNode和TaskTracker的硬件规则可以采用以下方案:
- 4个磁盘驱动器(单盘1-2T),支持JBOD(just a bunch of disks,磁盘簇)
- 2个4核CPU,至少2-2.5GHz
- 16-24GB内存
- 千兆以太网
NameNode提供整个HDFS文件系统的命名空间管理、块管理等所有服务,所以需要更多的RAM,并且需要优化RAM的内存通道带宽,可以采用以下方案:
- 8-12个磁盘驱动器(单盘1-2T)
- 2个4核/8核CPU
- 16-72GB内存
- 千兆/万兆以太网
SecondaryNameNode在小型集群可以和NameNode共用一台机器,较大的集群可以采用与NameNode一样的硬件
集群网络拓扑
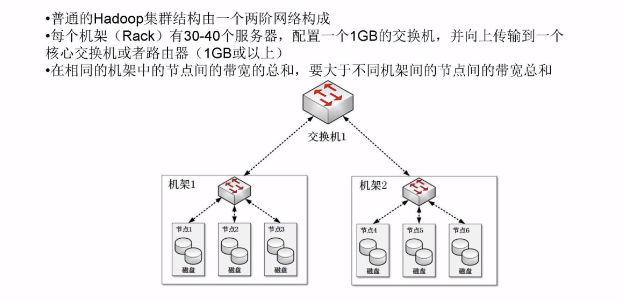
集群建立与安装
- 自动化部署:Docker等
集群基准测试
- Hadoop自带一些基准测试程序
在云计算环境中实用Hadoop
企业不需要自己部署集群,直接在云上部署
- 可以在Amazon EC2中运行Hadoop



