
一、Hive基础
1、Hive数据类型
(1)原始类型
| 类型 | 描述 | 示例 |
|---|---|---|
Boolean |
true、false |
TRUE |
TINYINT |
-128~127 | 1Y |
SMALLINT |
-32768~32767 | 1S |
INT |
4个字节的带符号整数 | 1 |
BIGINT |
8字节带符号整数 | 1L |
FLOAT |
4字节单精度浮点数 | 1.0 |
DOUBLE |
8字节双精度浮点数 | 1.0 |
DECIMAL |
任意精度的带符号小数 | 1.0 |
STRING |
字符串 | ‘ABC’ |
VARCHAR |
长字符串 | |
CHAR |
固定长度字符串 | |
BINARY |
字节数组 | |
TIMESTAMP |
时间戳,纳秒精度 | |
DATE |
日期 | 2019-10-08 |
(2)复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
ARRAY |
有序的的同类型的集合 | array(1,2) |
MAP |
key-value key必须为原始类型,value可以任意类型 |
map(‘a’,1,’b’,2) |
UNION |
在有限取值范围内的一个值 | create_union(1,’a’,63) |
STRUCT |
字段集合,类型可以不同 | struct(‘1’,1,1.0) |
2、Hive数据库操作
(1)创建数据库
-- 命令
CREATE DATABASE|SCHEMA [IF NOT EXISTS] ;
-- 例子
CREATE DATABASE IF NOT EXISTS database_name;
(2)删除数据库
-- 命令
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
-- 例子
DROP DATABASE IF EXISTS userdb;
3、Hive表操作
(1)创建表
-- 命令
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
-- 例子
CREATE TABLE IF NOT EXISTS employee
(eid int,
name String,
salary String,
destination String)
COMMENT ‘Employee details’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LINES TERMINATED BY ‘\n’
STORED AS TEXTFILE;
(2)修改表
-- 重命名表
ALTER TABLE name RENAME TO new_name
ALTER TABLE employee RENAME TO emp;
-- 添加列
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE employee ADD COLUMNS (
dept STRING COMMENT 'Department name');
-- 删除列
ALTER TABLE name DROP [COLUMN] column_name
-- 更改列属性
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE employee CHANGE salary salary Double;
-- 替换列
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
ALTER TABLE employee REPLACE COLUMNS (
eid INT empid Int,
ename STRING name String);
(3)删除表
DROP TABLE [IF EXISTS] table_name;
4、Hive表数据操作
(1)插入数据
LOAD DATA:从HDFS中加载数据会直接move!
--命令
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
--例子
LOAD DATA LOCAL INPATH '/home/user/sample.txt' OVERWRITE INTO TABLE employee;
INSERT INTO
insert into table account
select id, age, name from account_tmp;
INSERT OVERWRITE
insert overwrite table account2
select id, age, name from account_tmp;
注意:
insert overwrite会覆盖已经存在的数据,假如原始表使用overwrite上述的数据,先现将原始表的数据remove,再插入新数据。
insert into只是简单的插入,不考虑原始表的数据,直接追加到表中。
(2)修改数据
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
(3)删除数据
DELETE FROM tablename [WHERE expression]
5、Hive分区操作
(1)添加分区
-- 命令
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION (p_column = p_col_value, p_column = p_col_value, ...)
[LOCATION 'location1'] (p2_column = p2_col_value, p2_column = p2_col_value, ...) [LOCATION 'location2'] ...;
-- 例子
ALTER TABLE employee ADD PARTITION (year=’2013’) location '/2012/part2012';
(2)重命名分区
-- 命令
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
-- 例子
ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj=’1203’);
(3)删除分区
-- 命令
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;
-- 例子
ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);
6、Hive内置运算符
(1)关系运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A = B | 所有基本类型 | |
| A != B | 所有基本类型 | |
| A < B | 所有基本类型 | |
| A <= B | 所有基本类型 | |
| A > B | 所有基本类型 | |
| A >= B | 所有基本类型 | |
| A IS NULL | 所有类型 | |
| A IS NOT NULL | 所有类型 | |
| A LIKE B | 字符串 | TRUE,如果字符串模式A匹配到B, 否则FALSE。 |
| A RLIKE B | 字符串 | TRUE:A任何子字符串匹配Java正则表达式B; |
| A REGEXP B | 字符串 | 等同于RLIKE. |
(2)算术运算符
| 运算符 | 操作 | 描述 | |
|---|---|---|---|
| A + B | 所有数字类型 | ||
| A - B | 所有数字类型 | ||
| A * B | 所有数字类型 | ||
| A / B | 所有数字类型 | ||
| A % B | 所有数字类型 | ||
| A & B | 所有数字类型 | A和B的按位与结果 | |
| A \ | B | 所有数字类型 | A和B的按位或结果 |
| A ^ B | 所有数字类型 | A和B的按位异或结果 | |
| ~ A | 所有数字类型 | A按位非的结果 |
(3)逻辑运算符
| 运算符 | 操作 | 描述 | ||
|---|---|---|---|---|
| A AND B | Boolean | 与 | ||
| A && B | Boolean | |||
| A OR B | Boolean | 或 | ||
| A \ | \ | B | Boolean | |
| NOT A | Boolean | 非 | ||
| ! A | Boolean |
(4)复杂运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A[n] | A是一个数组,n是一个int | 它返回数组A的第n+1个元素,第一个元素的索引0。 |
| M[Key] | M 是一个 Map |
它返回对应于映射中关键字的值。 |
| S.x | S 是一个结构 | 它返回S的s字段 |
7、Hive内置函数
-- 返回BIGINT最近的double值。
round(double a)
-- 返回最大BIGINT值等于或小于double。
floor(double a)
-- 它返回最小BIGINT值等于或大于double。
ceil(double a)
-- 它返回一个随机数,从行改变到行。
rand()
rand(int seed)
-- 它返回从A后串联B产生的字符串
concat(string A, string B, ...)
-- 它返回一个起始位置start到A结束的子字符串
substr(string A, int start)
-- 返回从给定长度length的从起始位置start开始的字符串。
substr(string A, int start, int length)
-- 它返回转换所有字符为大写的字符串。
upper(string A)
ucase(string A)
-- 它返回转换所有字符为小写的字符串。
lower(string A)
lcase(string A)
-- 它返回字符串从A两端修剪空格的结果
trim(string A)
-- 它返回从A左边开始修整空格产生的字符串(左手侧)
ltrim(string A)
-- 它返回从A右边开始修整空格产生的字符串(右侧)
rtrim(string A)
-- 它返回将A中的子字符串B替换为C的全新字符串
regexp_replace(string A, string B, string C)
-- 它返回在映射类型或数组类型的元素的数量。
size(Map)
size(Array)
-- 将字段expr的数据类型转换为type。如果转换不成功,返回的是NULL。
cast( as )
-- 将10位的时间戳值unixtime转为日期函数
from_unixtime(int unixtime, 'yyyy-MM-dd HH:mm:ss')
-- 返回一个字符串时间戳的日期部分:to_date("1970-01-01 00:00:00") = "1970-01-01"
to_date(string timestamp, 'yyyy-MM-dd')
-- 返回指定日期的unix时间戳
unix_timestamp(string date, 'yyyy-MM-dd HH:mm:ss') -- date的形式必须为’yyyy-MM-dd HH:mm:ss’的形式
unix_timestamp() -- 返回当前时间的unix时间戳
-- 返回时间字段中的年月日
year(string date, 'yyMMdd') -- 年
month(string date, 'yyMMdd') -- 月
day(string date, 'yyMMdd') -- 日
-- 返回时间字段是本年的第多少周
weekofyear(string date, 'yyMMdd')
-- 返回enddate与begindate之间的时间差的天数
datediff(string enddate,string begindate)
select datediff(‘2016-06-01’,’2016-05-01’) from Hive_sum limit 1;
-- 返回date增加days天后的日期
date_add(string date,int days)
-- 返回date减少days天后的日期
date_sub(string date,int days)
-- 提取从基于指定的JSON路径的JSON字符串JSON对象,并返回提取的JSON字符串的JSON对象。
get_json_object(string json_string, string path)
-- 返回检索行的总数。
count(*)
count(expr)
-- 返回该组或该组中的列的不同值的分组和所有元素的总和。
sum(col)
sum(DISTINCT col)
-- 返回上述组或该组中的列的不同值的元素的平均值。
avg(col)
avg(DISTINCT col)
-- 返回该组中的列的最大最小值。
min(col)
max(col)
8、Hive视图和索引
(1)创建视图
-- 命令
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT table_comment]
AS SELECT ...
-- 例子
CREATE VIEW emp_30000 AS
SELECT * FROM employee
WHERE salary>30000;
(2)删除视图
DROP VIEW view_name
(3)创建索引
-- 命令
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name=property_value, ...)]
[IN TABLE index_table_name]
[PARTITIONED BY (col_name, ...)]
[
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)]
-- 例子:使用字段 Id, Name, Salary, Designation, 和 Dept创建一个名为index_salary的索引,对employee 表的salary列索引。
CREATE INDEX inedx_salary ON TABLE employee(salary)
AS 'org.apache.hadoop.Hive.ql.index.compact.CompactIndexHandler';
(4)删除索引
DROP INDEX ON
二、Hive进阶
1、Hive SELECT 数据
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[ORDER BY col_list]
[LIMIT number];
2、命令执行顺序
-- 大致顺序
from... where.... select... group by... having ... order by...
备注:Hive语句和mysql都可以通过explain查看执行计划,使用explain + Hive语句
三、Hive原理
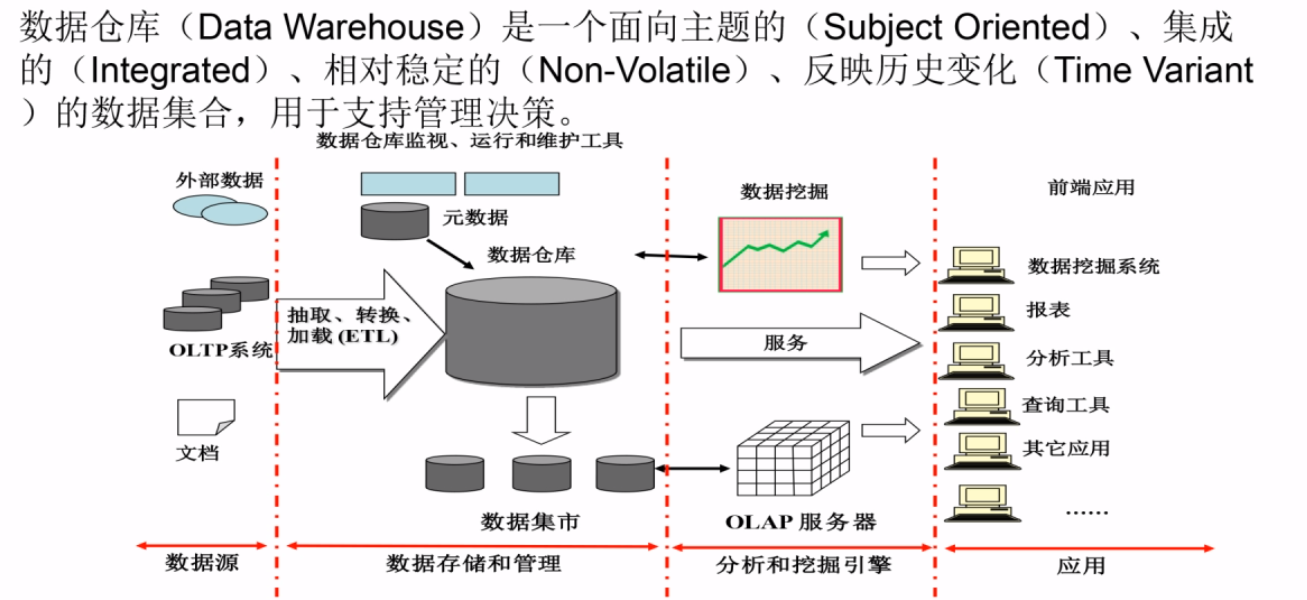
数据仓库概念
- Hive是数据仓库
- 数据仓库跟数据库的区别:
- 数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
- 数据仓库:数据仓库系统的应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
Hive简介
- Hadoop顶层的数据仓库工具
- 支持大数据存储与分析
- 依赖HDFS存储数据
- 依赖MapReduce处理数据
- 有类似SQL的查询语言-HiveQL
- 用户通过HiveQL运行MapReduce任务
- Hive适用于BI报表,Pig适合ETL过程,HBase提供数据的实时访问
Hive与传统Sql对比
| 对比项目 | Hive | 传统Sql |
|---|---|---|
| 数据插入 | 支持批量导入 | 支持单条和批量 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 支持 | 支持 |
| 分区 | 支持 | 支持 |
| 执行延迟 | 高 | 低 |
| 扩展性 | 好 | 有限 |
Hive系统架构
用户接口模块
CLI
- Shell命令行
- Karmasphere
HWI
- web接口
- Hue
JDBC
- Qubole
- Hive 的Java,与使用传统数据库JDBC的方式类似
ODBC
- Hive 的Java,与使用传统数据库JDBC的方式类似
Thrift Server
- RPC调用
驱动模块
- 编译器
- 优化器
- 执行器
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。
- 生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
元数据存储
- 元数据存储模块(metastore)是一个独立的关系型数据库,目前只支持 mysql、derby。
- Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
Hive工作原理
HQL转换成MapReduce作业的过程

注意:
- 当启动MR程序时,Hive本身不会生成MR算法程序,需要通过一个“Job执行计划”的XML文件驱动来执行内置的Mapper和Reducer模块
- Hive通过和JobTracker通信来初始化MR任务
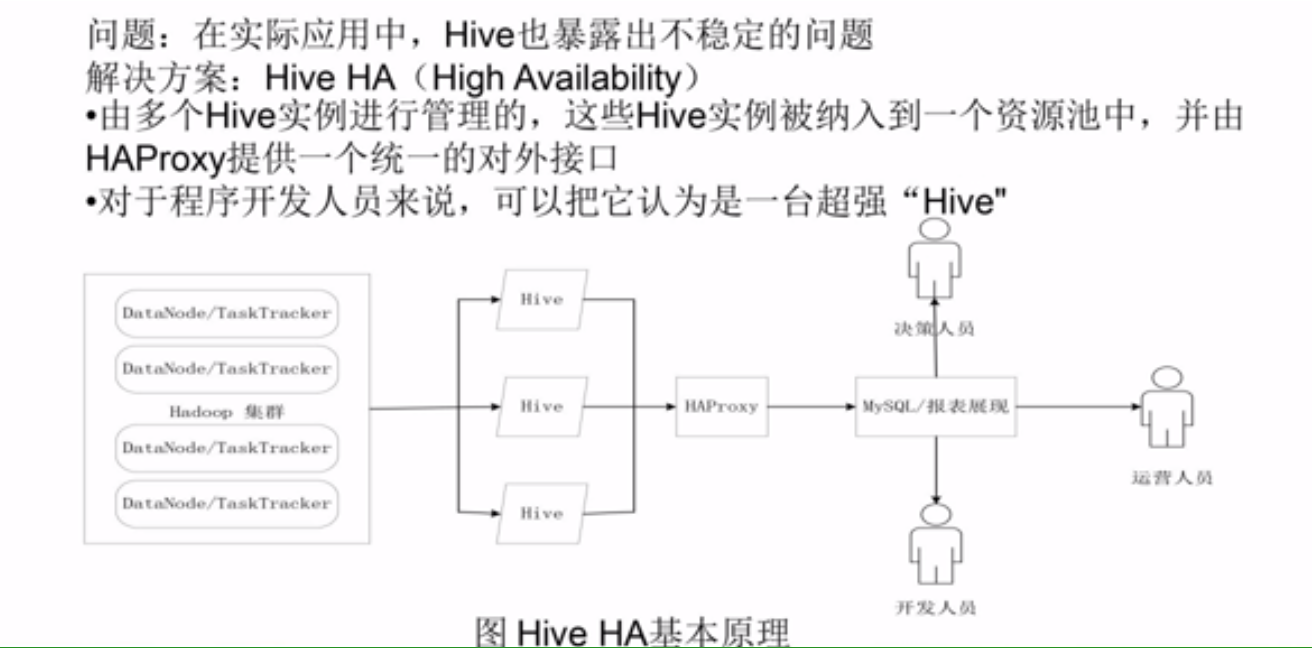
Hive HA基本原理
四、impala
- impala是由Cloudera公司开发的新型查询系统,提供SQL语义。
- 它的运行需要依赖Hive的元数据,能够查询PB级数据,在性能上比Hive高出3~30倍
- impala不需要将查询语句转为MR程序运行,而是使用传统的分布式查询引擎直接到HDFS上查询数据
- 详情请见
五、参考书籍
六、疑难解答
1、Hive 在指定位置添加字段
首先添加字段
alter table table_name add columns (c_time string comment '当前时间');其次更改字段的顺序
alter table table_name change c_time c_time string after address;添加字段后,重写表数据后,查询新字段为null的情况
alter table table_name drop partition(date_id='20210101') alter table table_name add partition(date_id='20210101')
2、Hive创建表时指定文件格式
TEXTFIEL
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。-- 固定格式 create table test1(str STRING) STORED AS TEXTFILE; -- 自定义格式 create table test1(str STRING) STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.Hive.ql.io.HiveIgnoreKeyTextOutputFormat'SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。-- 固定格式 create table test1(str STRING) STORED AS SEQUENCEFILE; -- 自定义格式 create table test1(str STRING) STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.Hive.ql.io.HiveSequenceFileOutputFormat'RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
-- 固定格式 create table test1(str STRING) STORED AS RCFILE; -- 自定义格式 create table test1(str STRING) STORED AS INPUTFORMAT 'org.apache.hadoop.Hive.ql.io.RCFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.Hive.ql.io.RCFileOutputFormat'
3、Hive同时拆分多列为多行
问题:
I’m Looking for a way to split the column based on comma delimited data. Below is my dataset
id col1 col2
1 5,6 7,8
I want to get the result
id col1 col2
1 5 7
1 6 8
答案:
You can use posexplode() to create position index columns for your split arrays. Then, select only those rows where the position indices are equal.
SELECT id, col3, col4
FROM test
lateral VIEW posexplode(split(col1,'\002')) col1 AS pos3, col3
lateral VIEW posexplode(split(col2,'\002')) col2 AS pos4, col4
WHERE pos3 = pos4;
Output:
id col3 col4
1 5 7
1 6 8
==补充==
- 单列explode
select
class,student_name
from
default.classinfo
lateral view explode(split(student,',')) t as student_name
- 单列posexplode
select
class,student_index + 1 as student_index,student_name
from
default.classinfo
lateral view posexplode(split(student,',')) t as student_index,student_name
- 多列explode
select
class,student_name,student_score
from
default.classinfo
lateral view posexplode(split(student,',')) sn as student_index_sn,student_name
lateral view posexplode(split(score,',')) sc as student_index_sc,student_score
where
student_index_sn = student_index_sc
4、 Hive或spark中执行sql字符常量包含;时会报错
比如
select instr(‘abc;abc’, ‘;’);
报错
NoViableAltException(-1@[147:1: selectExpression : ( expression | tableAllColumns );])
修改:需要将;改为ascii
select instr(‘abc\073abc’, ‘\073’);
5、如何在 Apache Hive 中解析 Json 数组
问题1:从json字符串中解析一个字段-get_json_object
hive> SELECT get_json_object('{"website":"www.iteblog.com","name":"过往记忆"}', '$.website');
OK
www.iteblog.com
问题2:从json字符串中解析多个字段-json_tuple
hive> SELECT json_tuple('{"website":"www.iteblog.com","name":"过往记忆"}', 'website', 'name');
OK
www.iteblog.com 过往记忆
问题3:从json数组中解析某一个字段-get_json_object
hive> SELECT get_json_object('[{"website":"www.iteblog.com","name":"过往记忆"}, {"website":"carbondata.iteblog.com","name":"carbondata 中文文档"}]', '$[0].website');
OK
www.iteblog.com
注意:这里与参考链接如何在 Apache Hive 中解析 Json 数组中不同的是,因为我用的是sparkSql,所以我用的是$[0].website,而参考链接使用的$.[0].website,我按照参考链接给的方法在Hive也select不出答案(可能是hive版本不同吧)
问题4:从json数组中解析多个字段-先explode再get_json_object或json_tuple
- explode将json数组用一行拆分成多行
- 然后再对其进行json字符串解析
详情请参考如何在 Apache Hive 中解析 Json 数组
6、删除表但是没删除hdfs数据,重建表并关联hdfs数据
7、HIVE将表划分测试集与训练集的方法
from (
select *, (rand() * 100 <= x) as is_test_set from my_table
) t
insert overwrite directory '/test_set' select * where is_test_set = true
insert overwrite directory '/training_set' select * where is_test_set = false;
8、HIVE日期操作
获取时间戳
select unix_timestamp('2015-04-30 13:51:20');
select unix_timestamp('2015-04-30');
转格式
select from_unixtime(1323308943,'yyyyMMdd');
select from_unixtime(unix_timestamp('2015-04-30', 'yyyy-MM-dd'), 'yyyyMMdd');
9、HIVE中distinct和group by的区别
前者是去重,后者是分组
reduce作业个数不同,distinct会在一个reduce中去重
10、count(*) 和 count(1)和count(列名)区别
* 执行效果上 :
count(\*)包括了所有的列,相当于行数,在统计结果的时候, 不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候, 不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数, 即某个字段值为NULL时,不统计。
* 执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1)的执行效率优于 count(\*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(\*) 最优。
11、求累计值
例子
| ds | cash | 累加值 |
|---|---|---|
| 20200101 | 10 | 10 |
| 20200102 | 20 | 30 |
SELECT
ds,
sum(cash),
sum(sum(cash)) over(distribute by substr(ds, 1, 6) sort by ds rows between UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative
from table_name
WHERE ds BETWEEN '20200901' AND '20201020'
group by ds
order by ds
12、四舍五入
select
round(cast(prob as double)),
round(cast(prob as double), 2),
floor(cast(prob as double)), --向下取整
ceil(cast(prob as double)), --向上取整
13、设置任务优先级
SET mapreduce.job.priority=VERY_HIGH;
14、求连续登录天数
SELECT
udid,
row2,
count(1) as num,
count(distinct ds) as dis_num
FROM
(
SELECT
udid,
ds,
substr(ds, 7, 2) as day_num,
dense_rank() OVER(PARTITION BY udid ORDER BY ds) as row1,
int(substr(ds, 7, 2))-dense_rank() OVER(PARTITION BY udid ORDER BY ds) as row2
FROM table_name
WHERE ds BETWEEN '20211101' AND '20211105'
) t1
GROUP BY udid, row2
15、求连续支付次数
SELECT
udid,
item_name,
row2_row1,
min(buy_time),
count(1) as cnt
FROM
(
select
udid,
item_name,
buy_time,
row_number() OVER(PARTITION BY udid, item_name ORDER BY buy_time) as row1,
row_number() OVER(PARTITION BY udid ORDER BY buy_time) as row2,
row_number() OVER(PARTITION BY udid ORDER BY buy_time) - row_number() OVER(PARTITION BY udid, item_name ORDER BY buy_time) as row2_row1
from table_name
) t1
GROUP BY udid, item_name, row2_row1
ORDER BY udid, item_name, row2_row1
16、长度表转宽度表
select user_no, str_to_map(concat_ws(',',sort_array(collect_set(concat_ws(':', message, detail))))) message1 from user_info group by user_no order by user_no
select user_no, message1['name'] name, message1['sex'] sex, message1['age'] age, message1['education'] education, message1['regtime'] regtime, message1['first_buytime'] first_buytimefrom (select user_no, str_to_map(concat_ws(',',collect_set(concat_ws(':', message, detail)))) message1 from user_info group by user_no order by user_no ) a
17、str_to_map函数
- Hive str_to_map函数
- 注意key,value中本身有分隔符的情况
str_to_map(concat_ws(',',collet_set(concat(orderstatus,'=',operatetime))),',','=')



